Here are my current predicted biomass values based on the linear equations at the bottom of the page. I didn’t include the code I used to generate them in this document, but I can send it over if you’d like to take a look. Right now, all the biomass values are in grams rather than kilograms. I’m not sure if that affects the predictions, but my plan was to scale them up to kilograms before rerunning the FRESH model.
I’m not sure if there are other tests that would be better to run instead. I could also use some guidance on which p-values should be considered “red flags” that suggest I need to use a different equation. I rounded everything to four decimal places to make the results easier to read, so any zeros you see are just very small values above zero
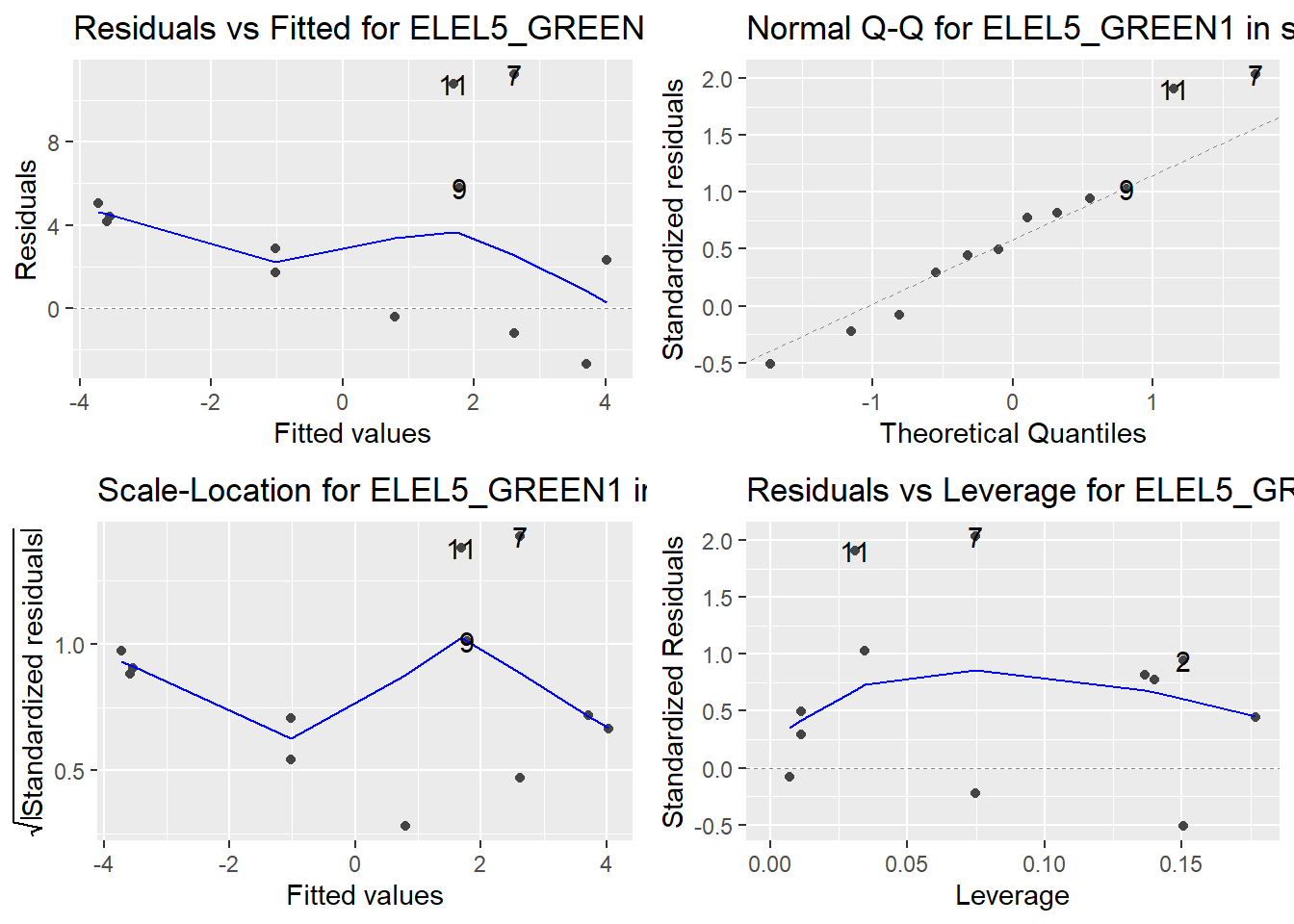
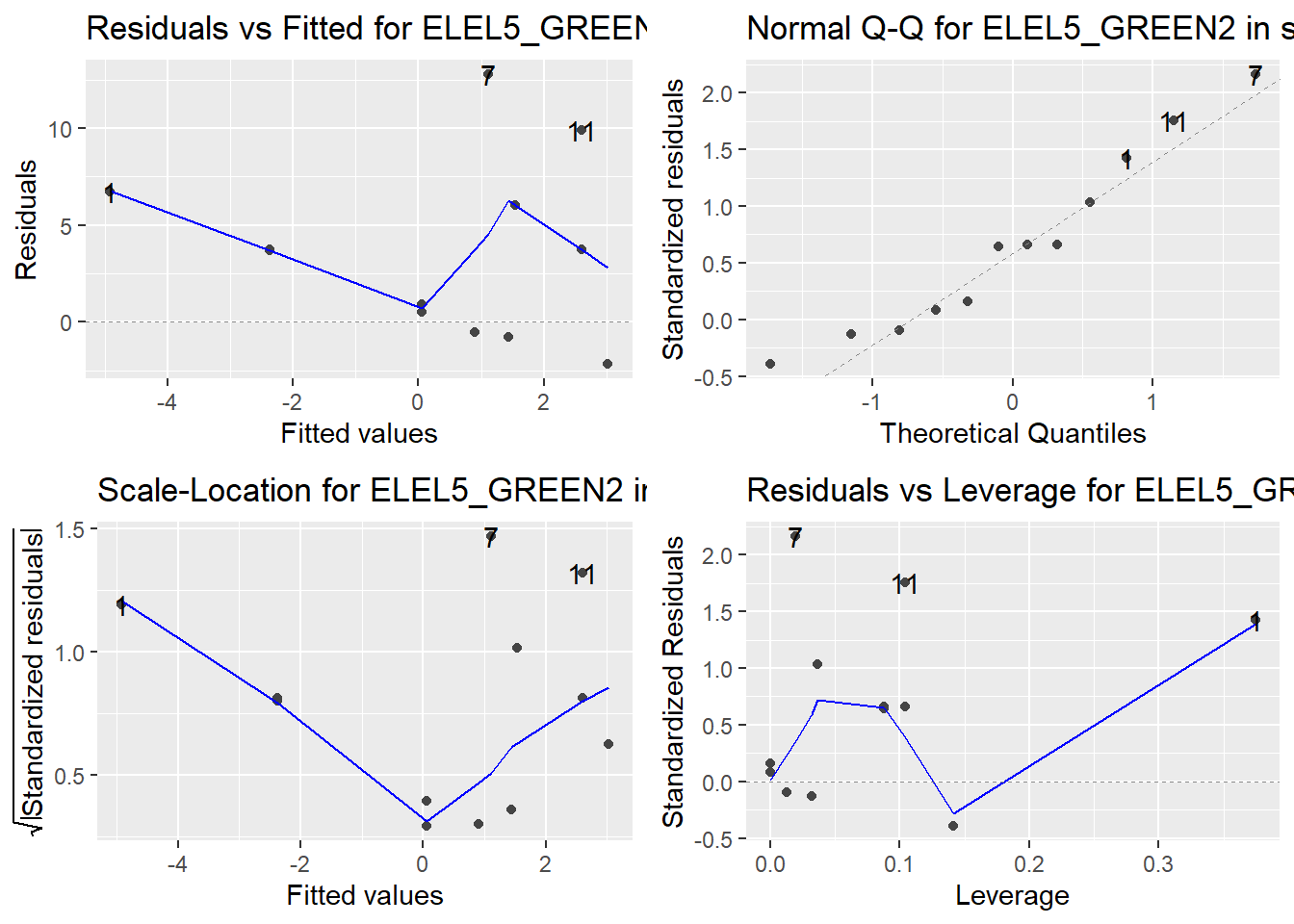
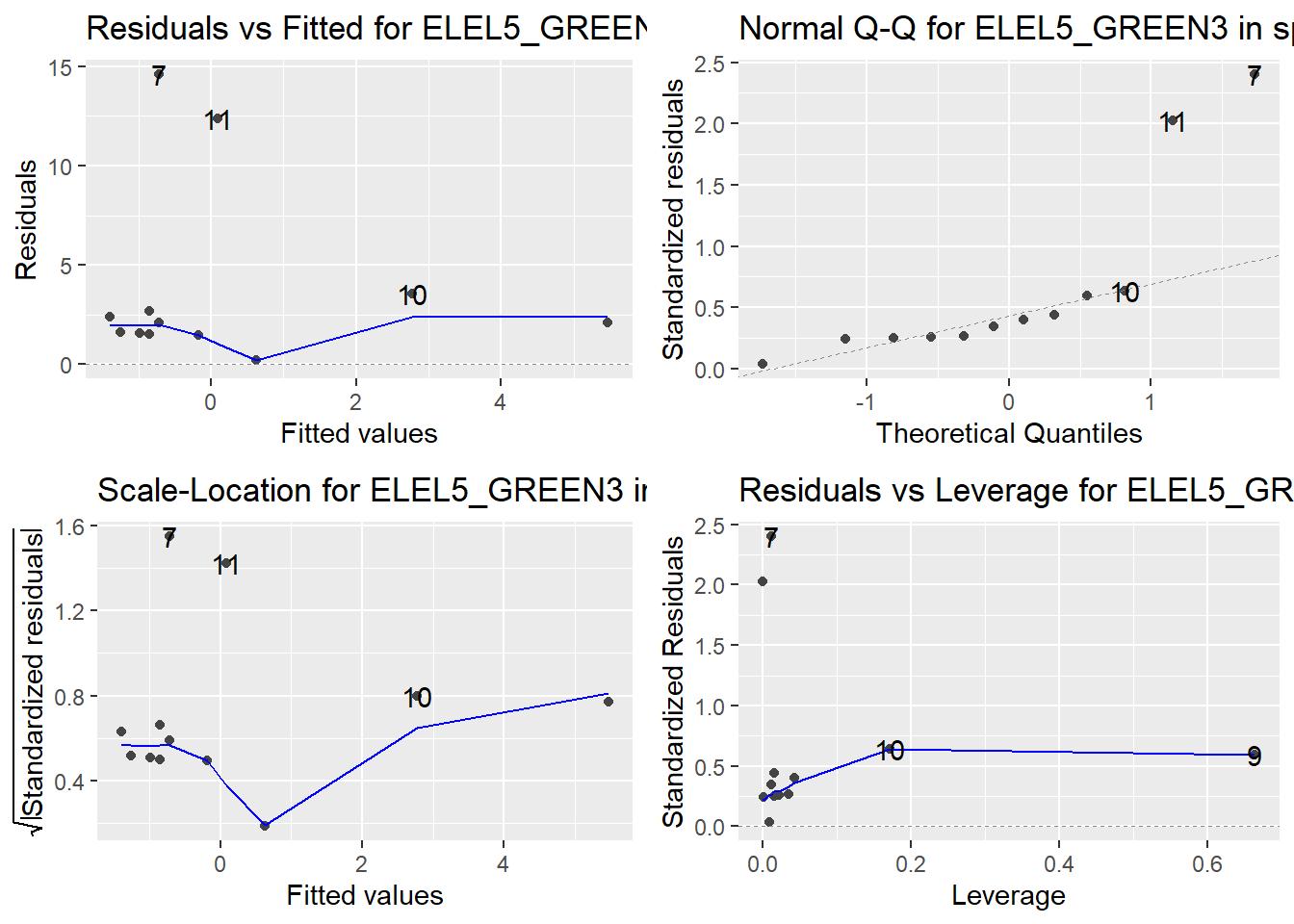
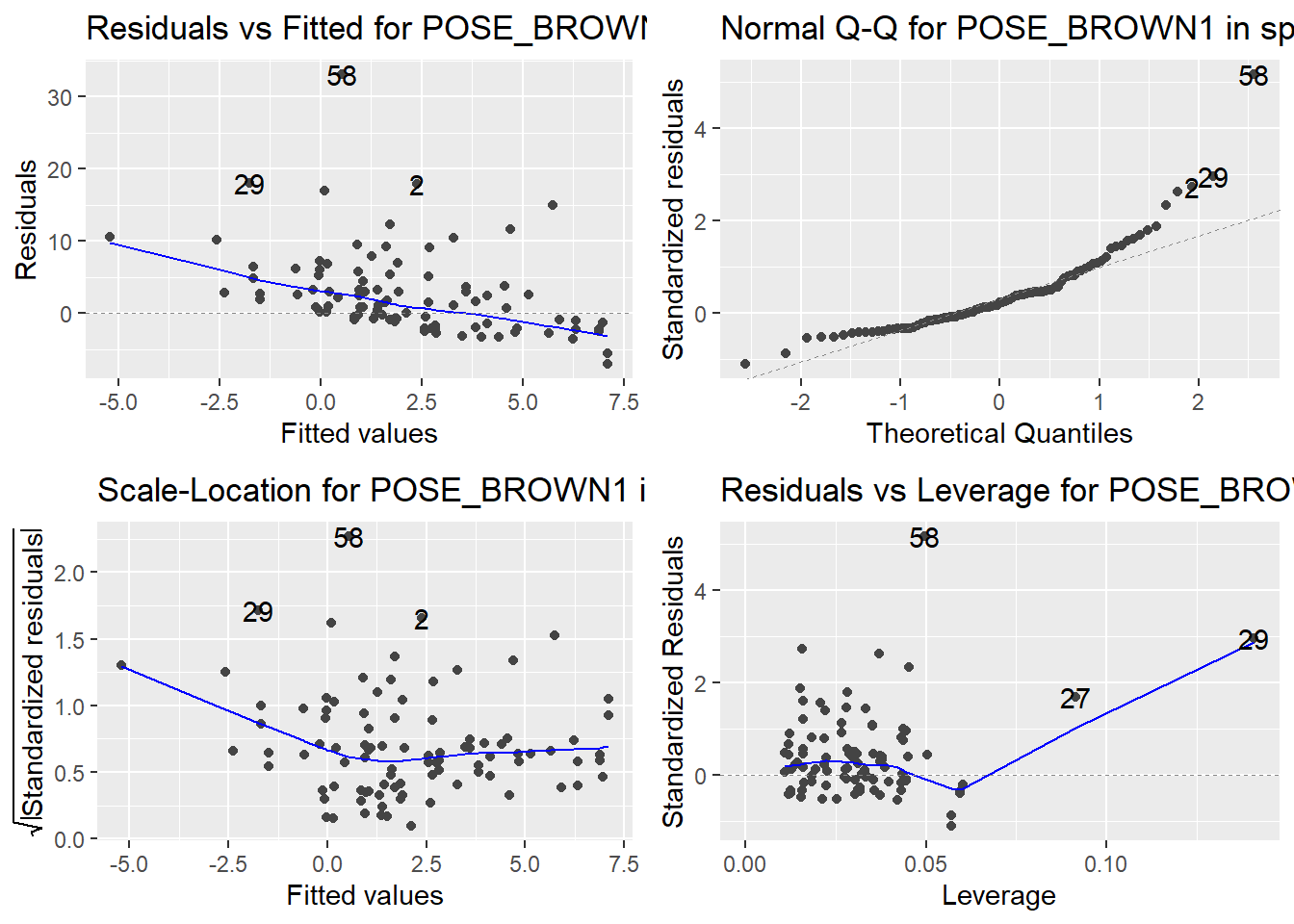
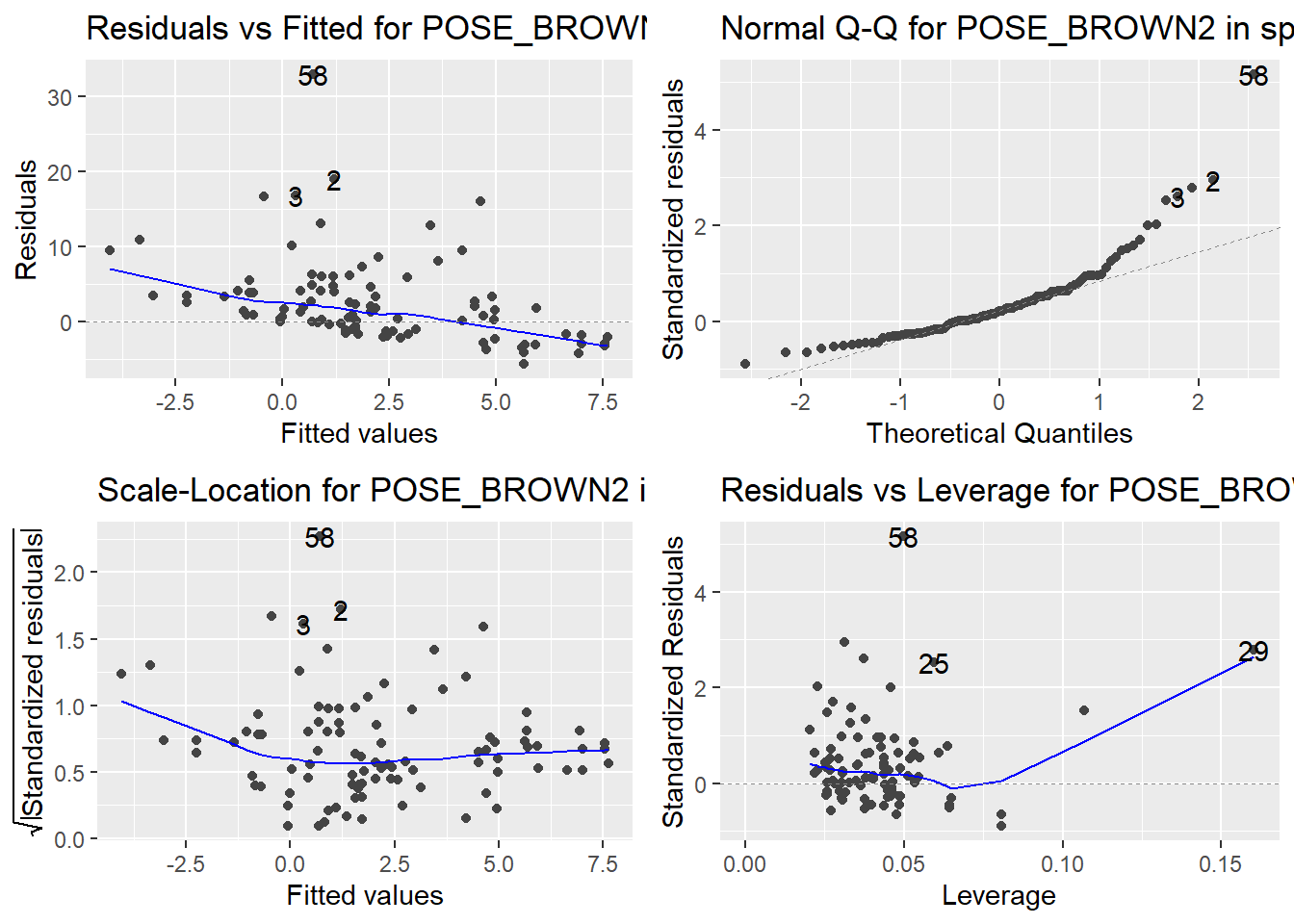
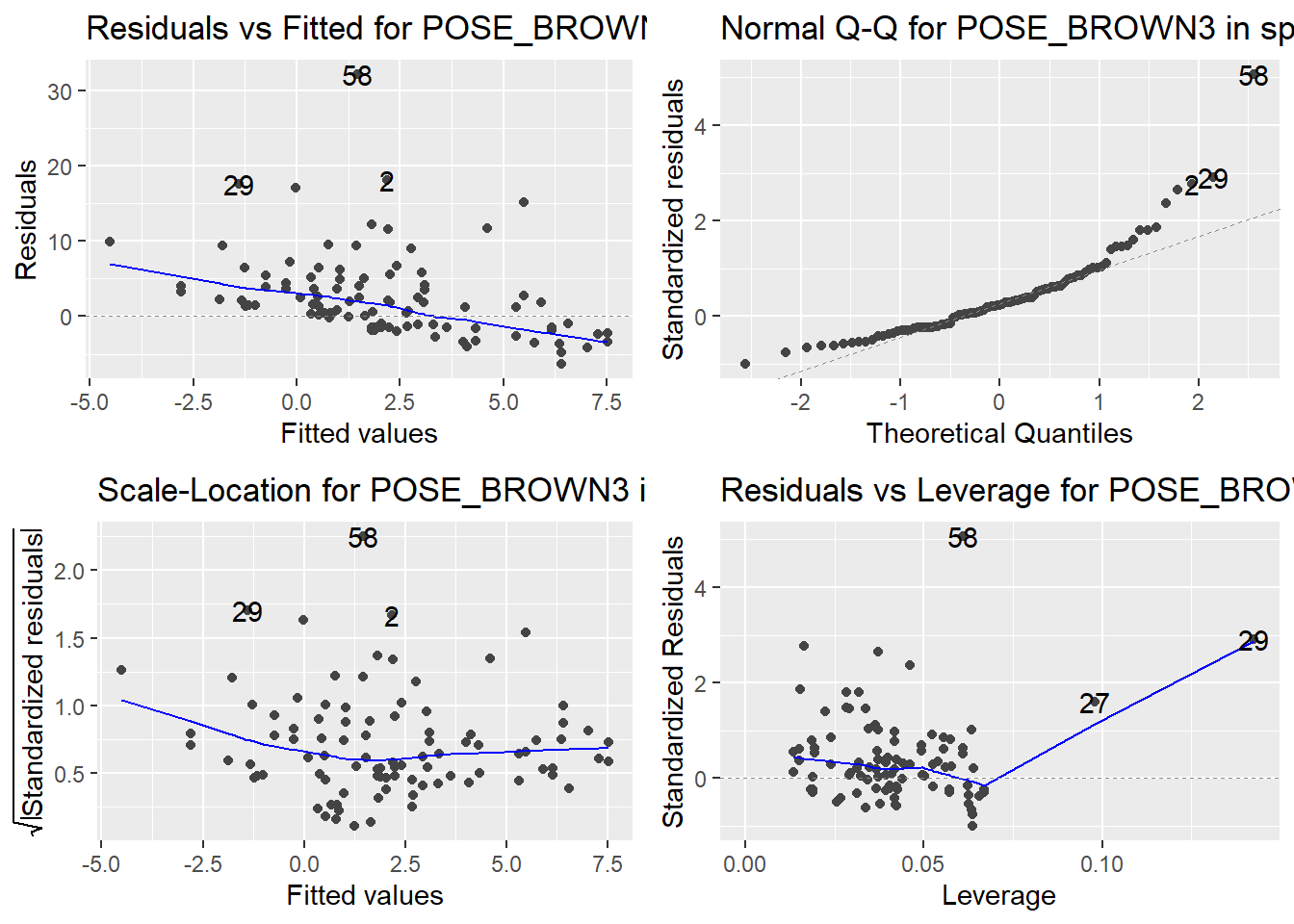
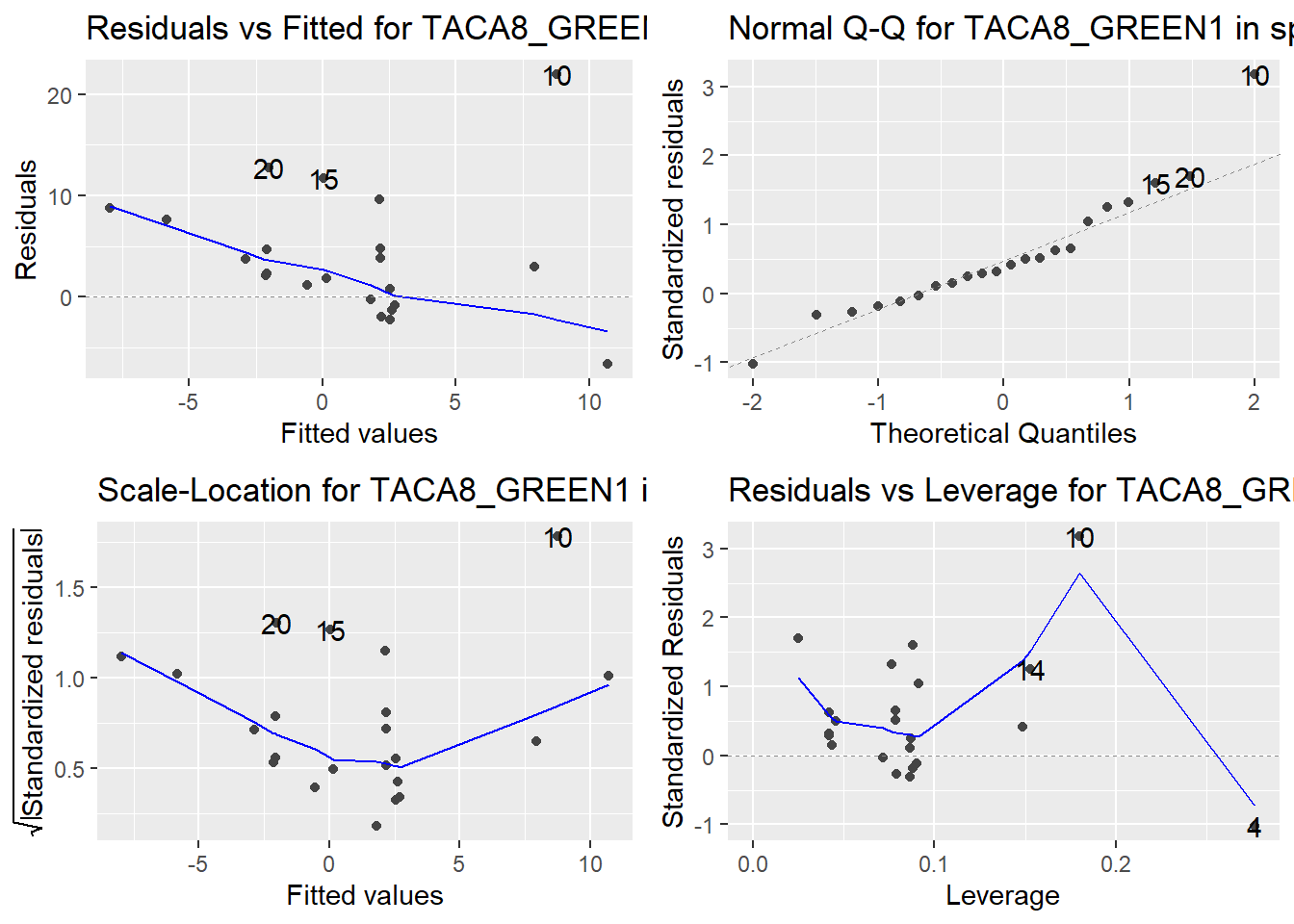
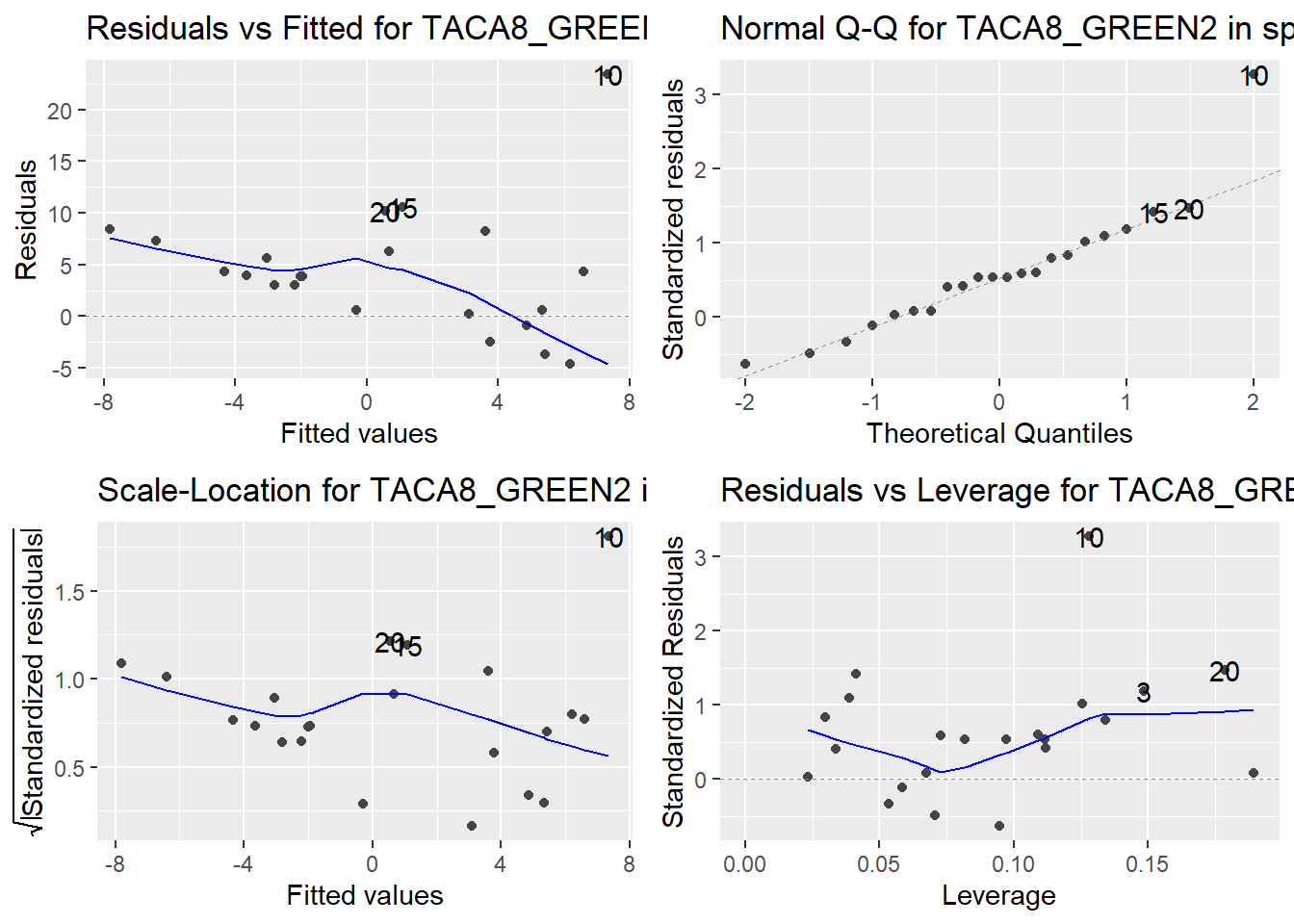
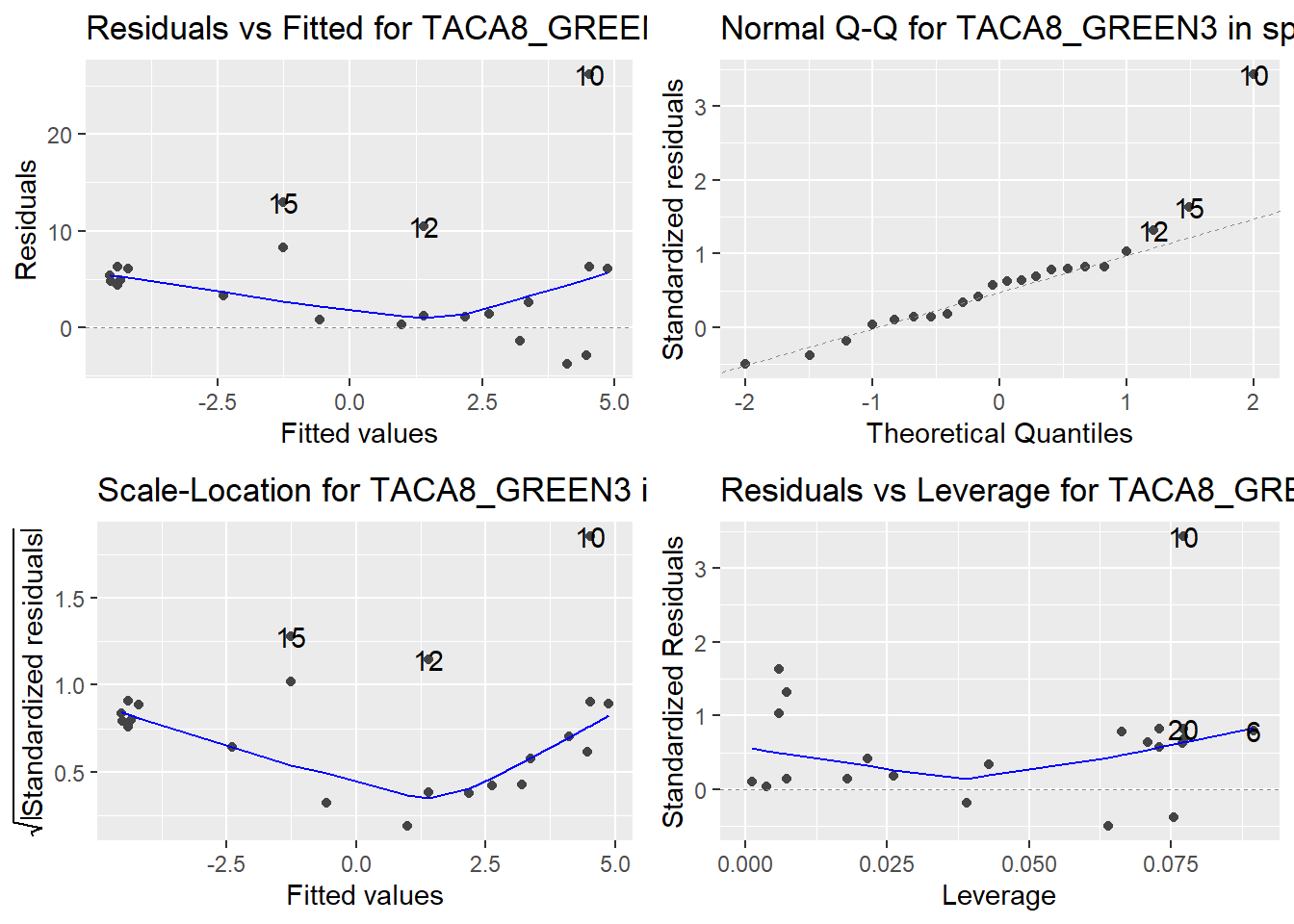
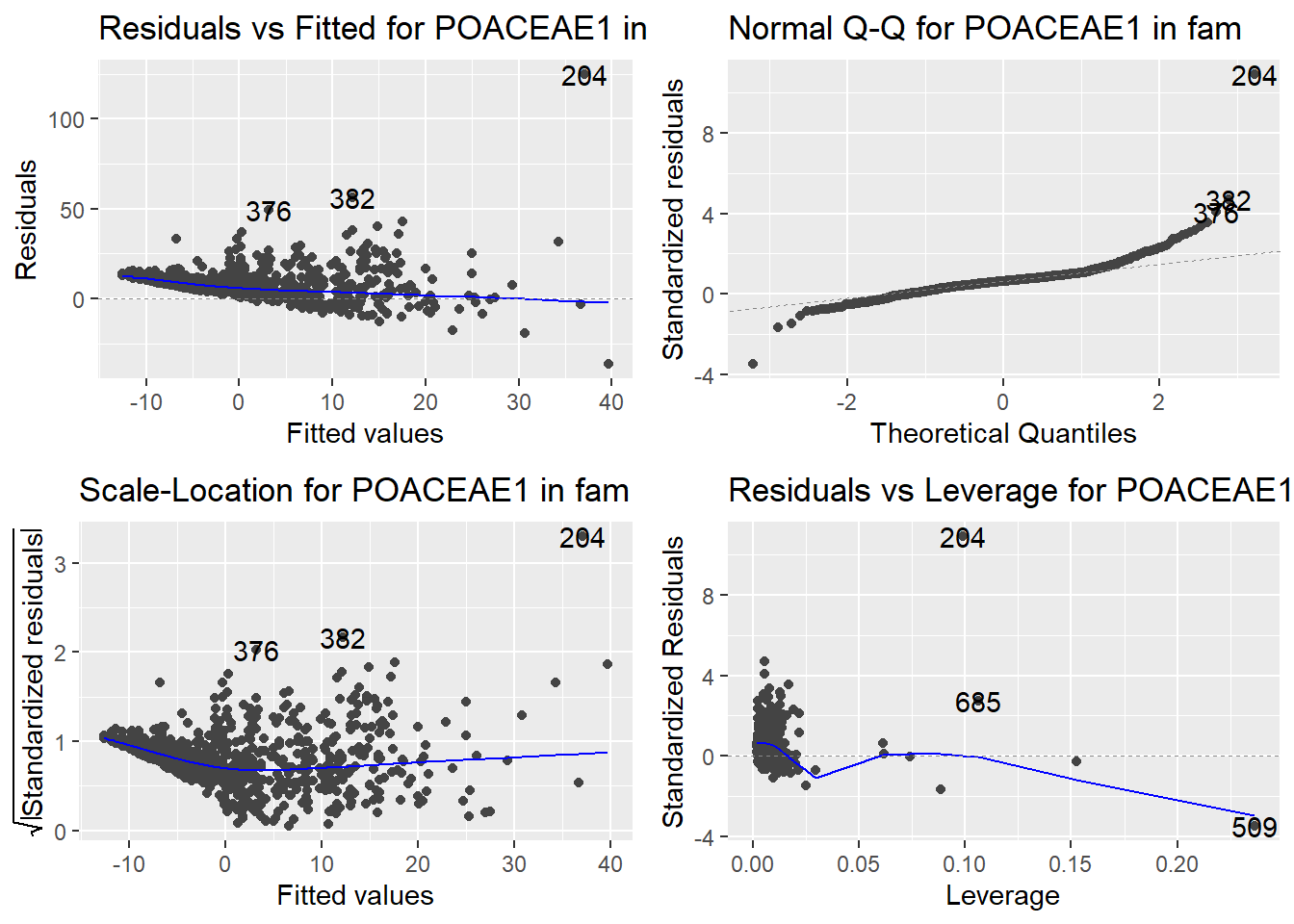
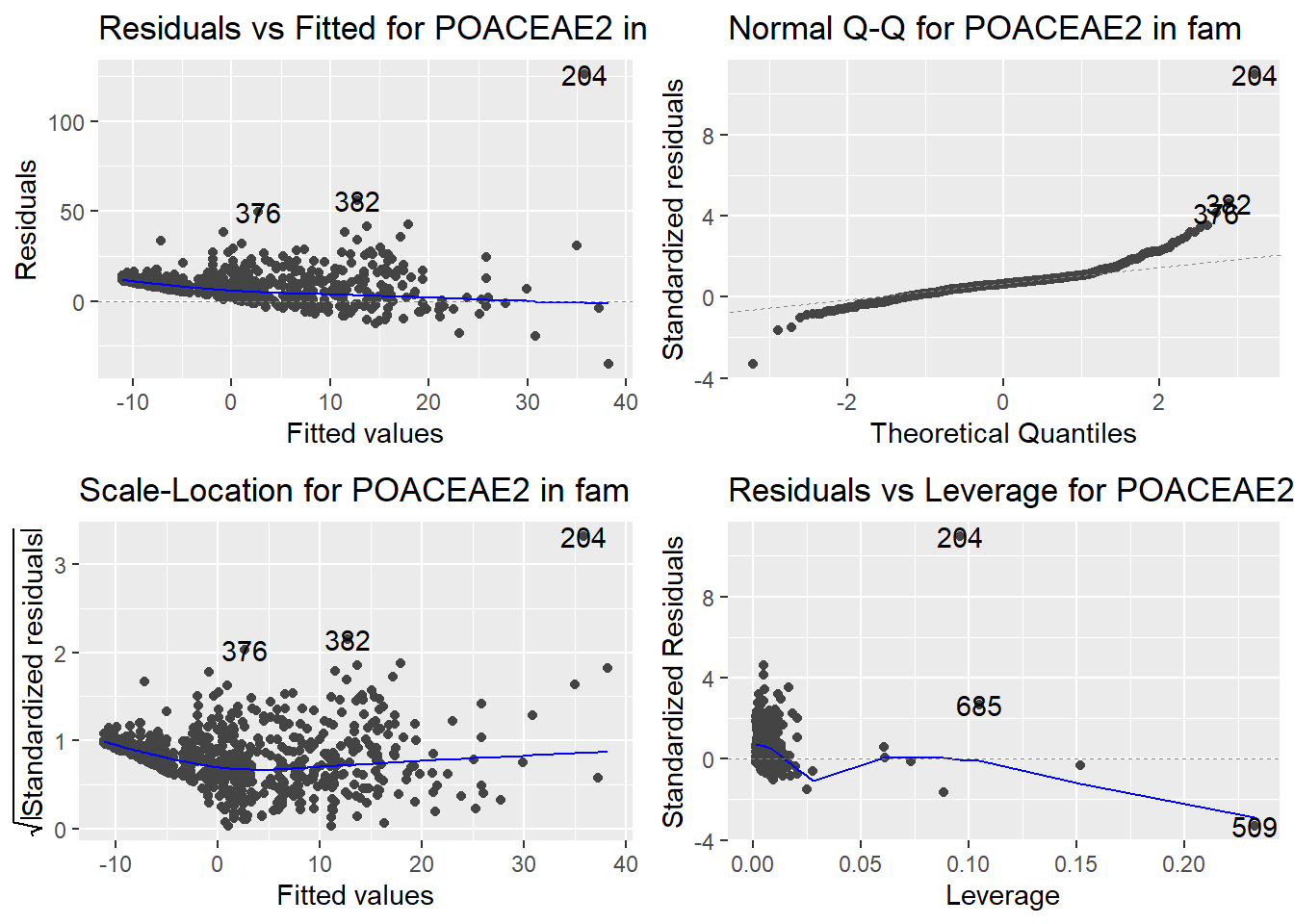
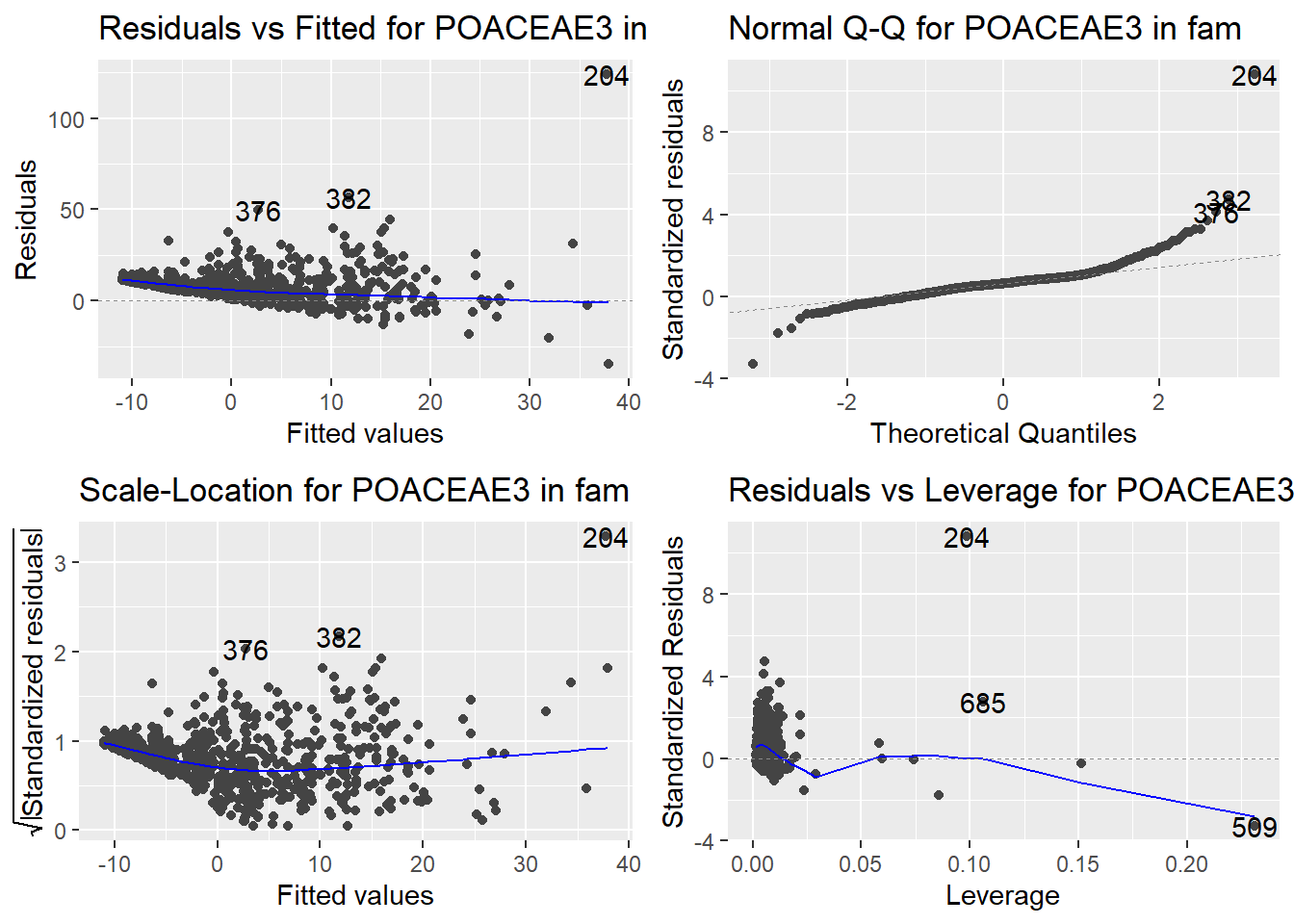
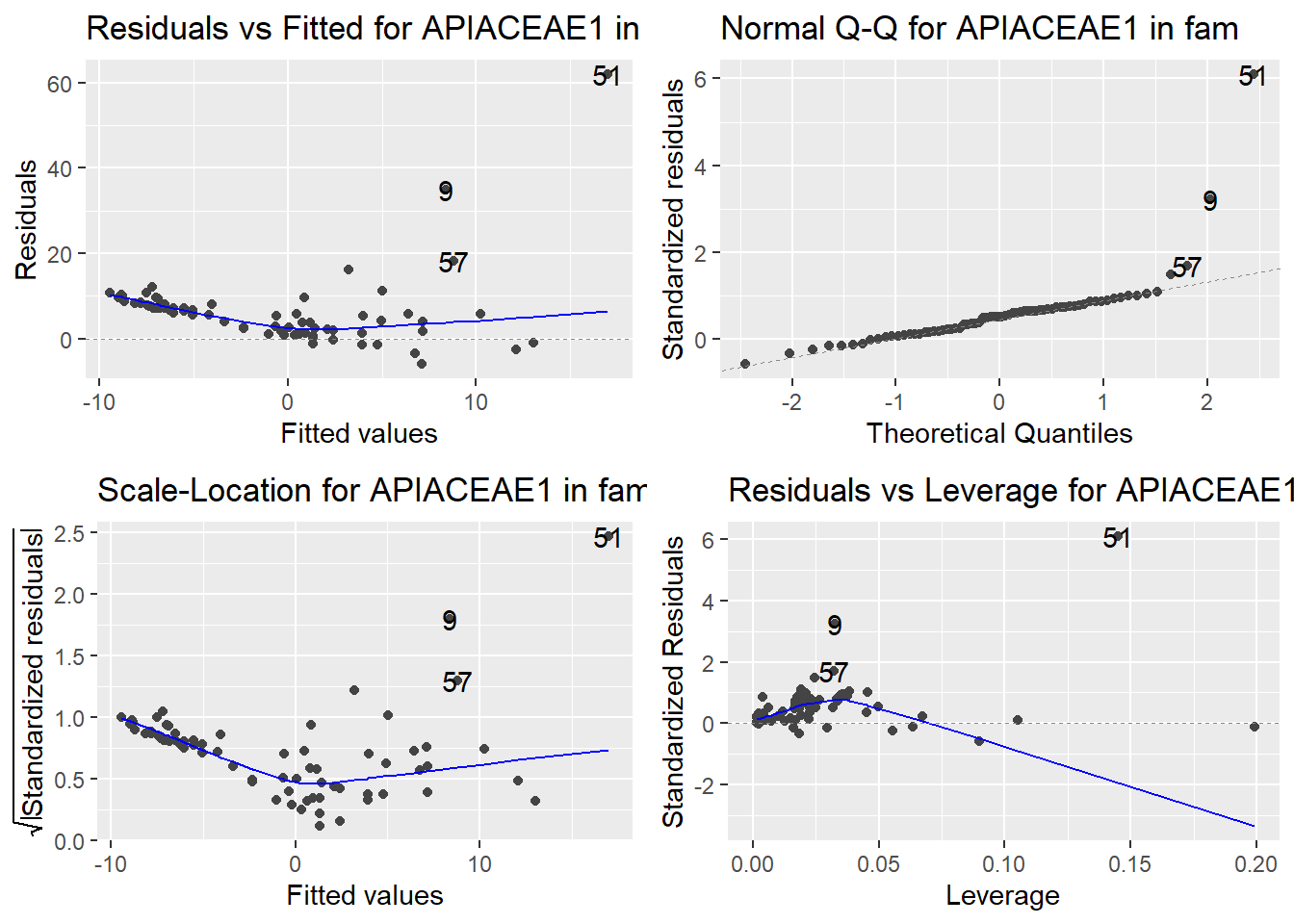
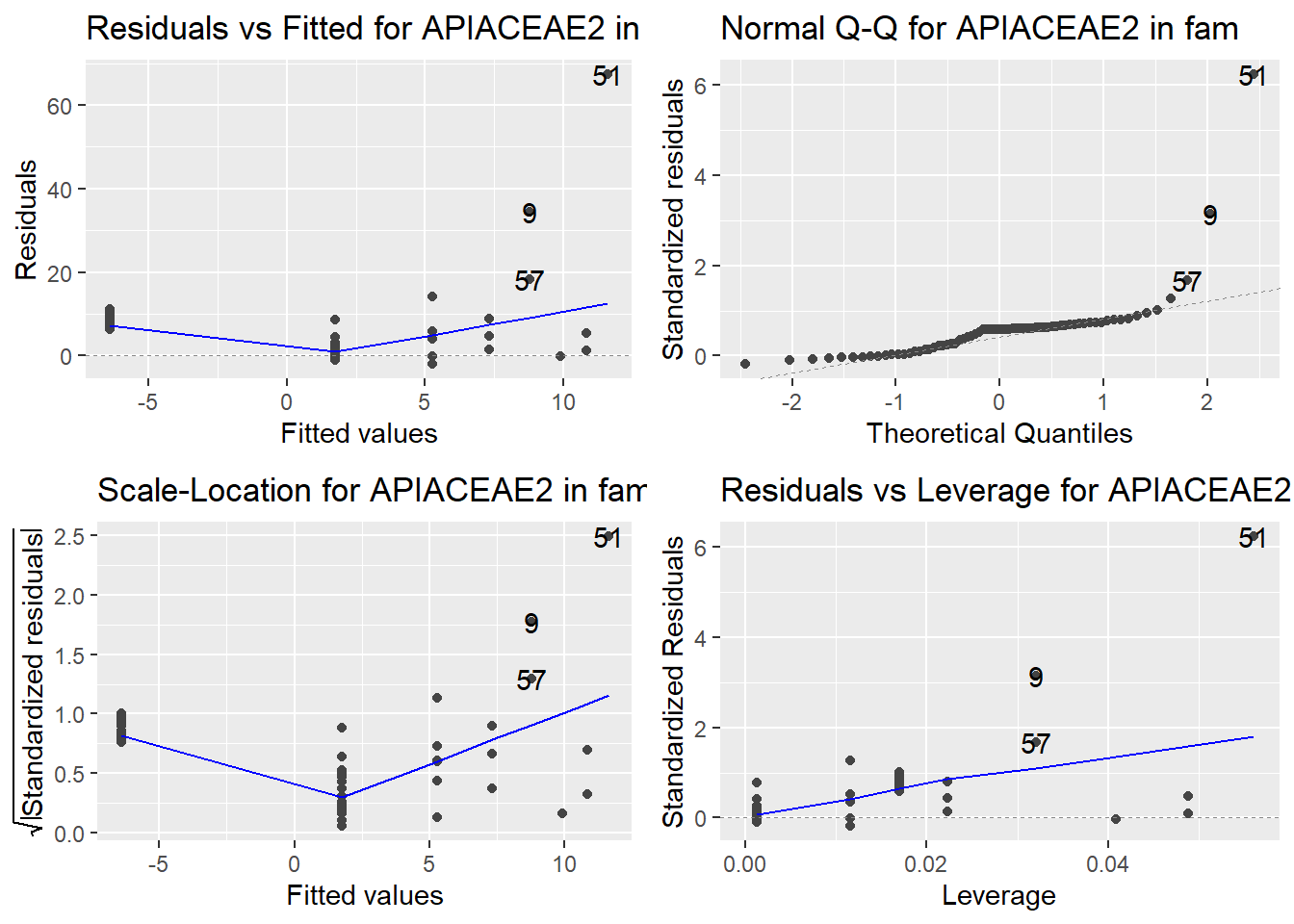
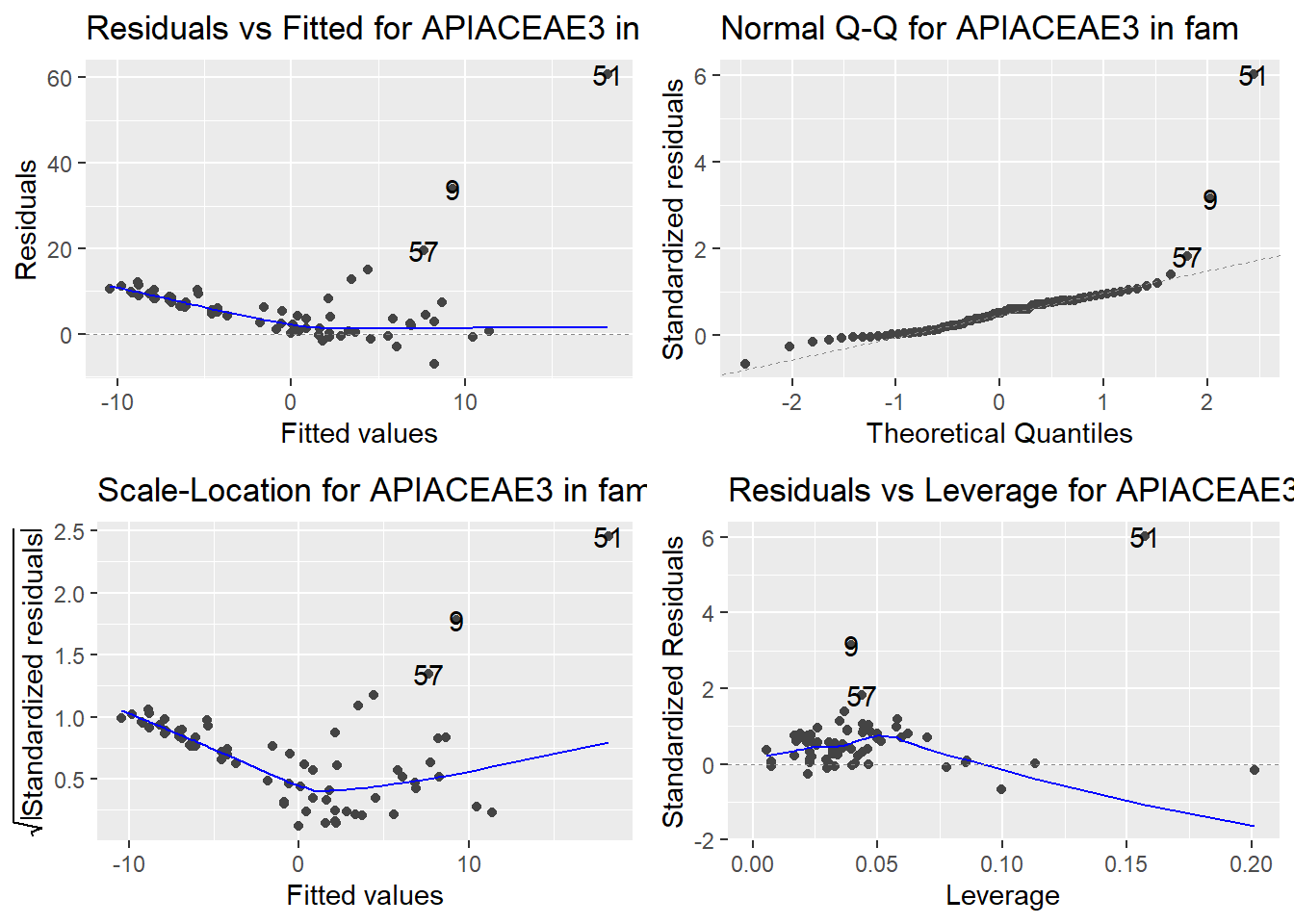
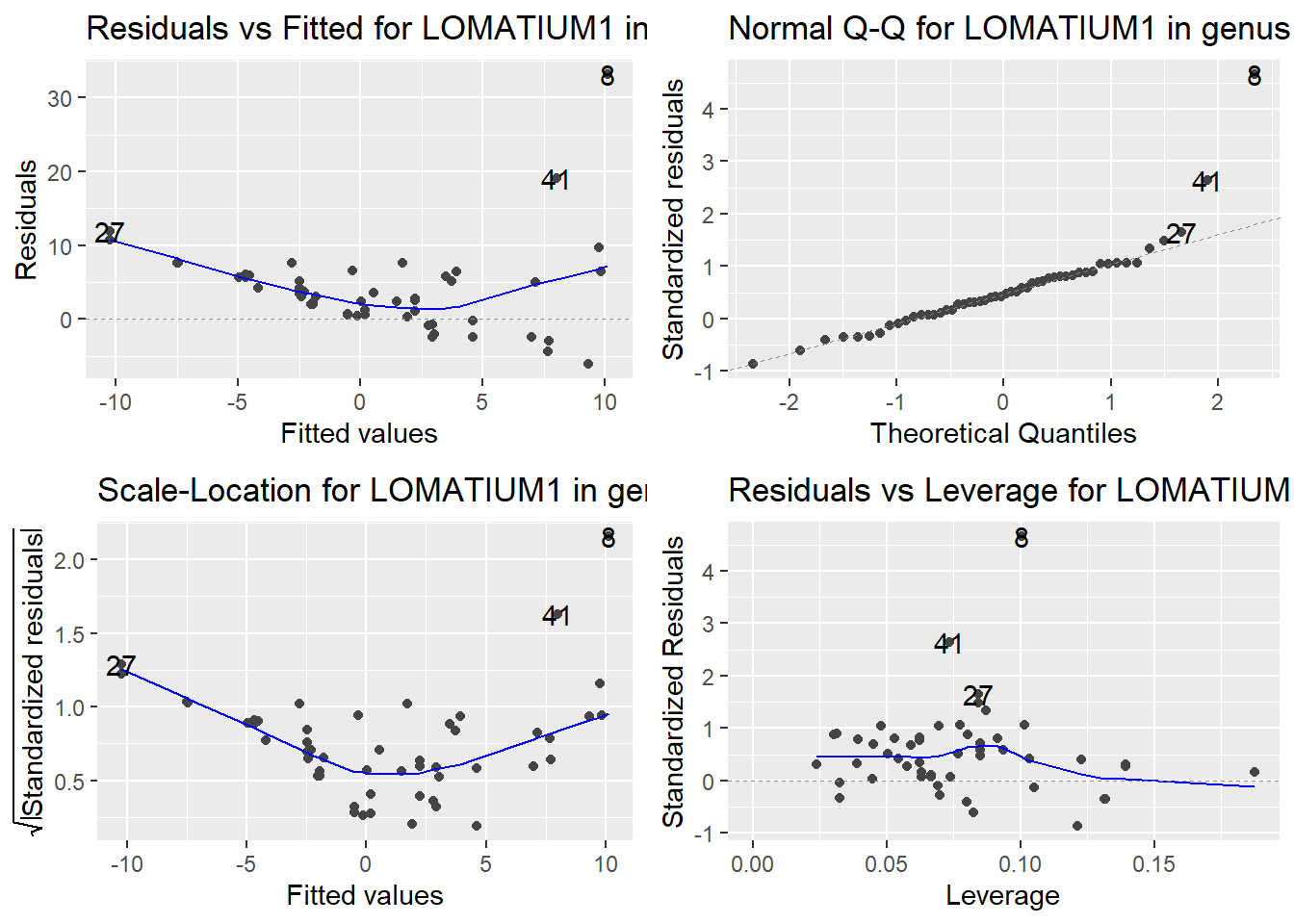
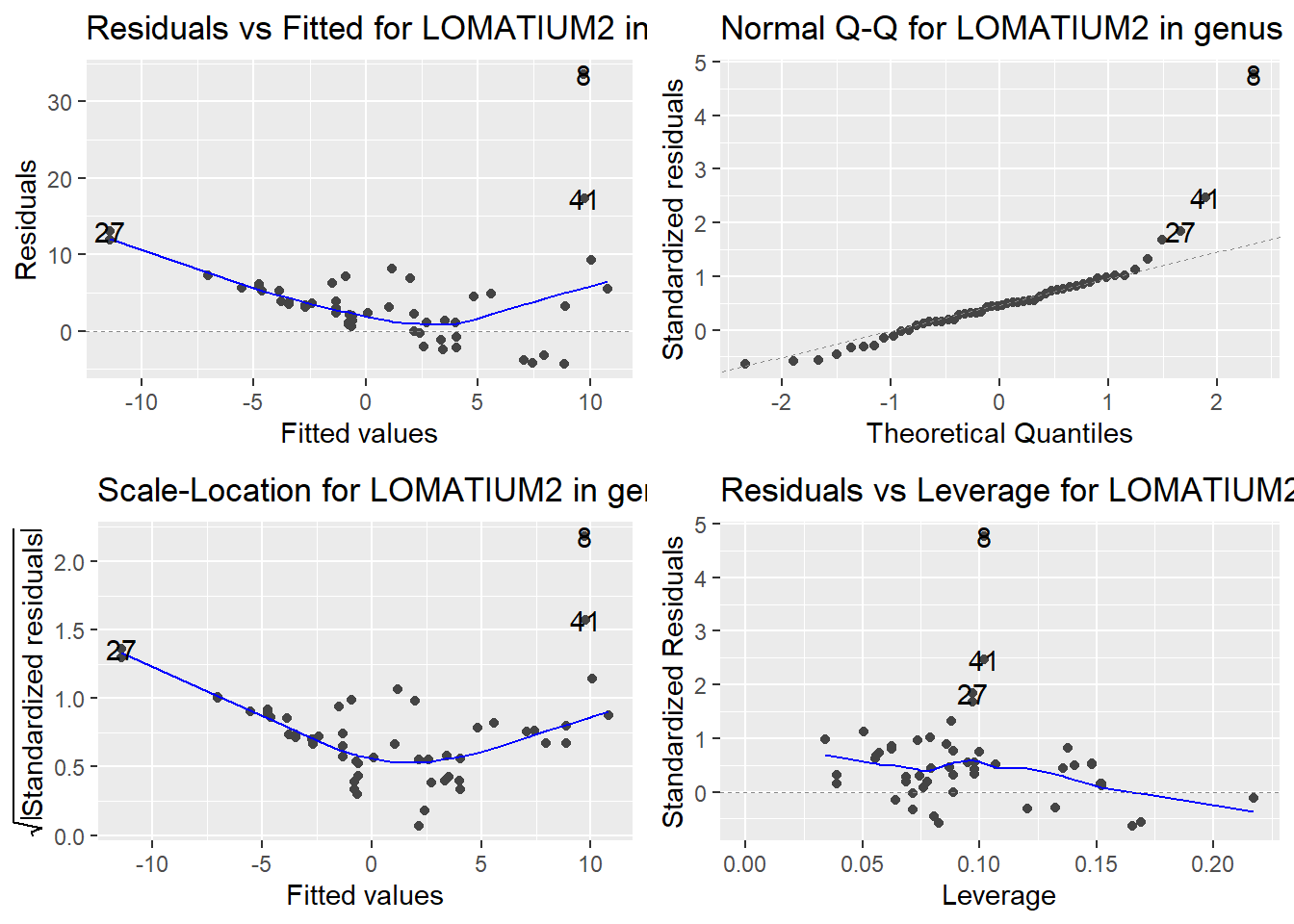
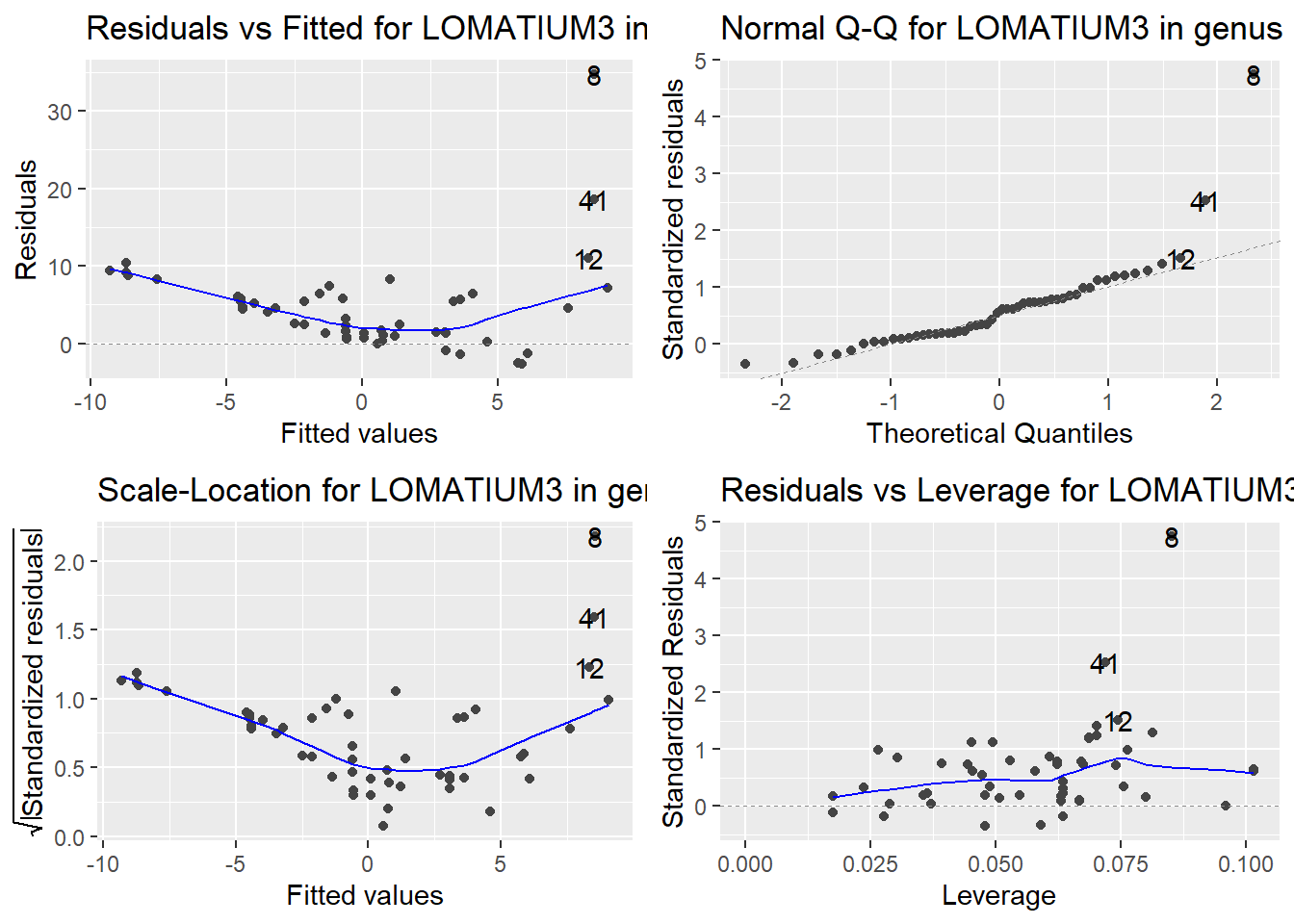
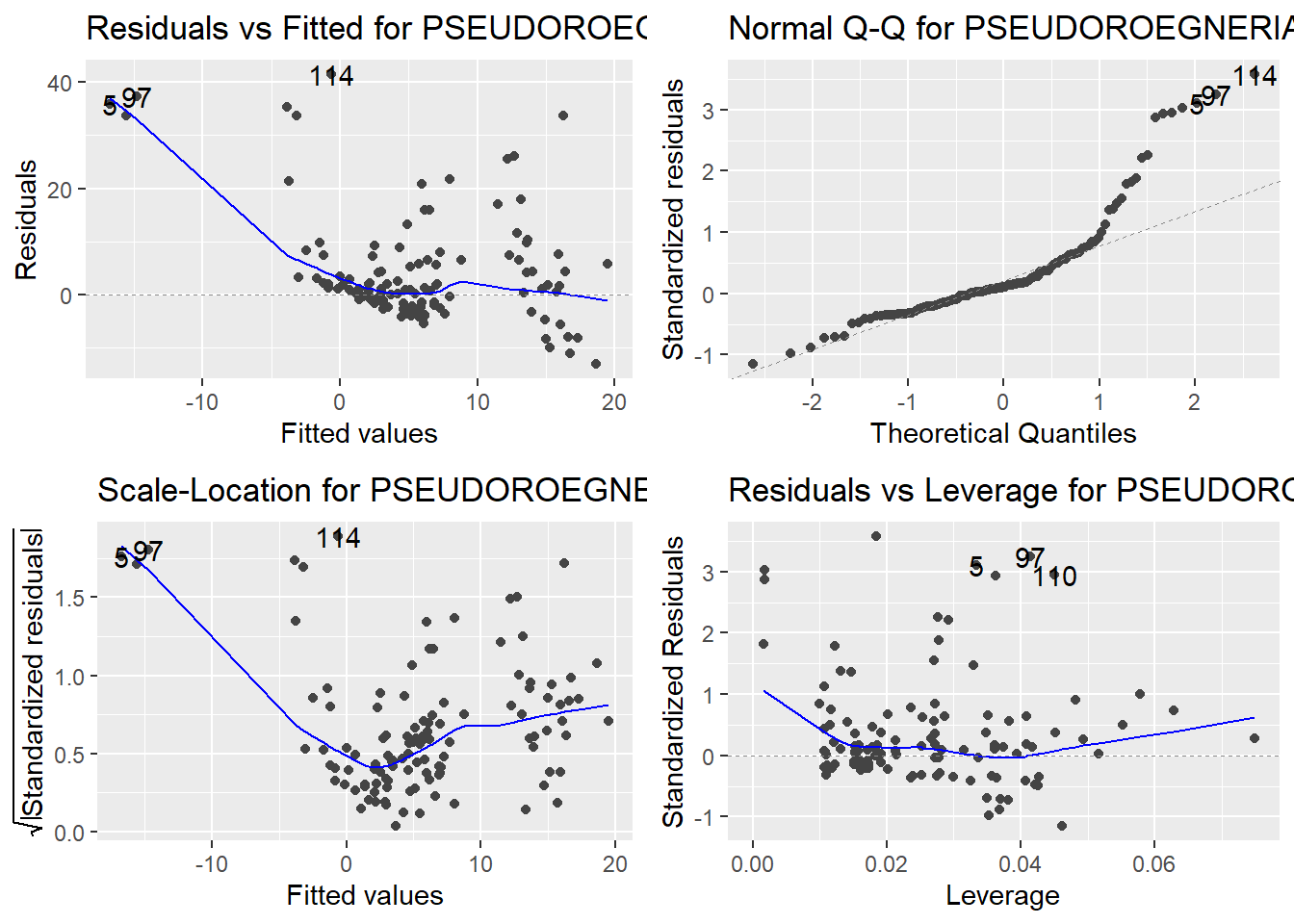
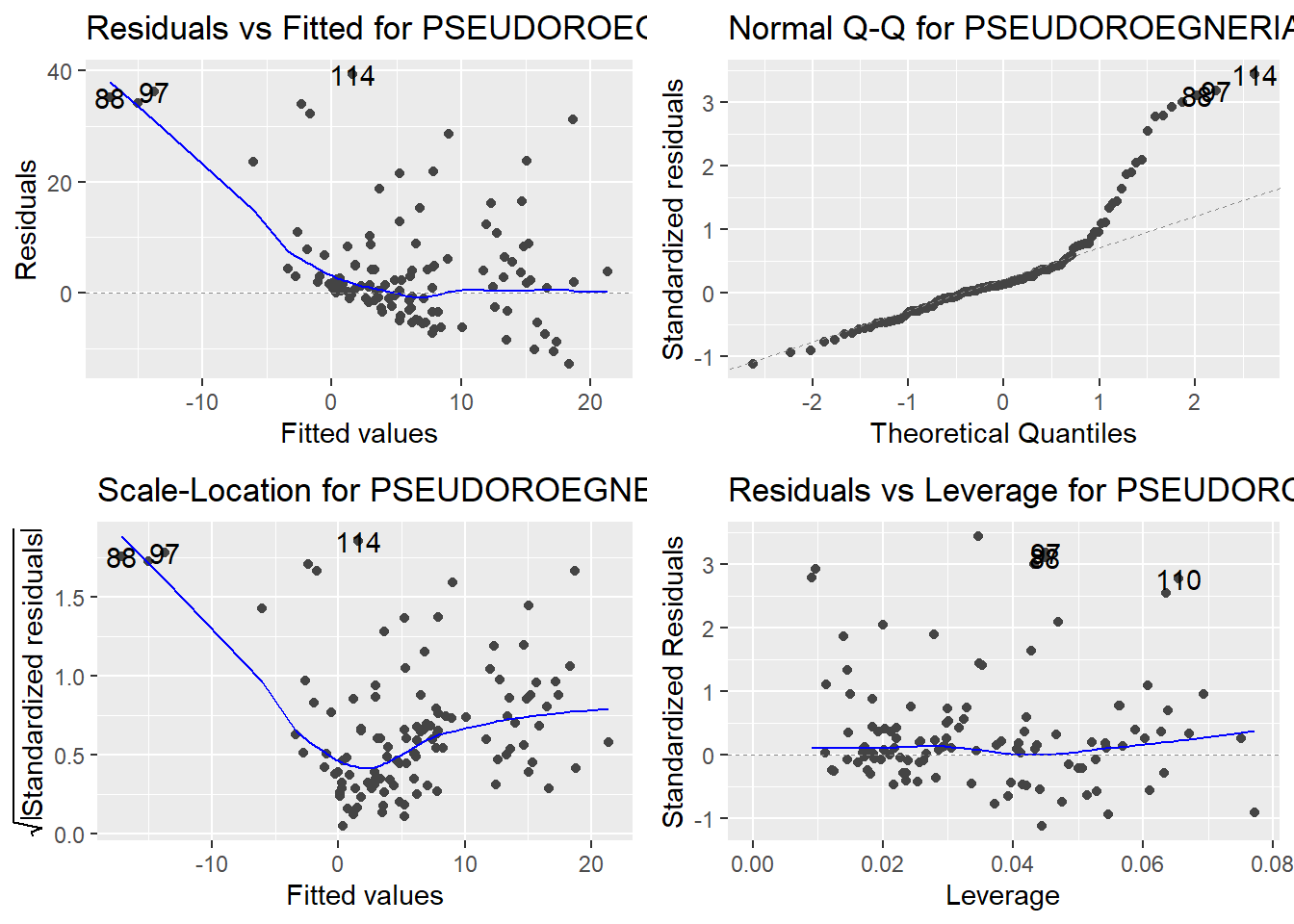
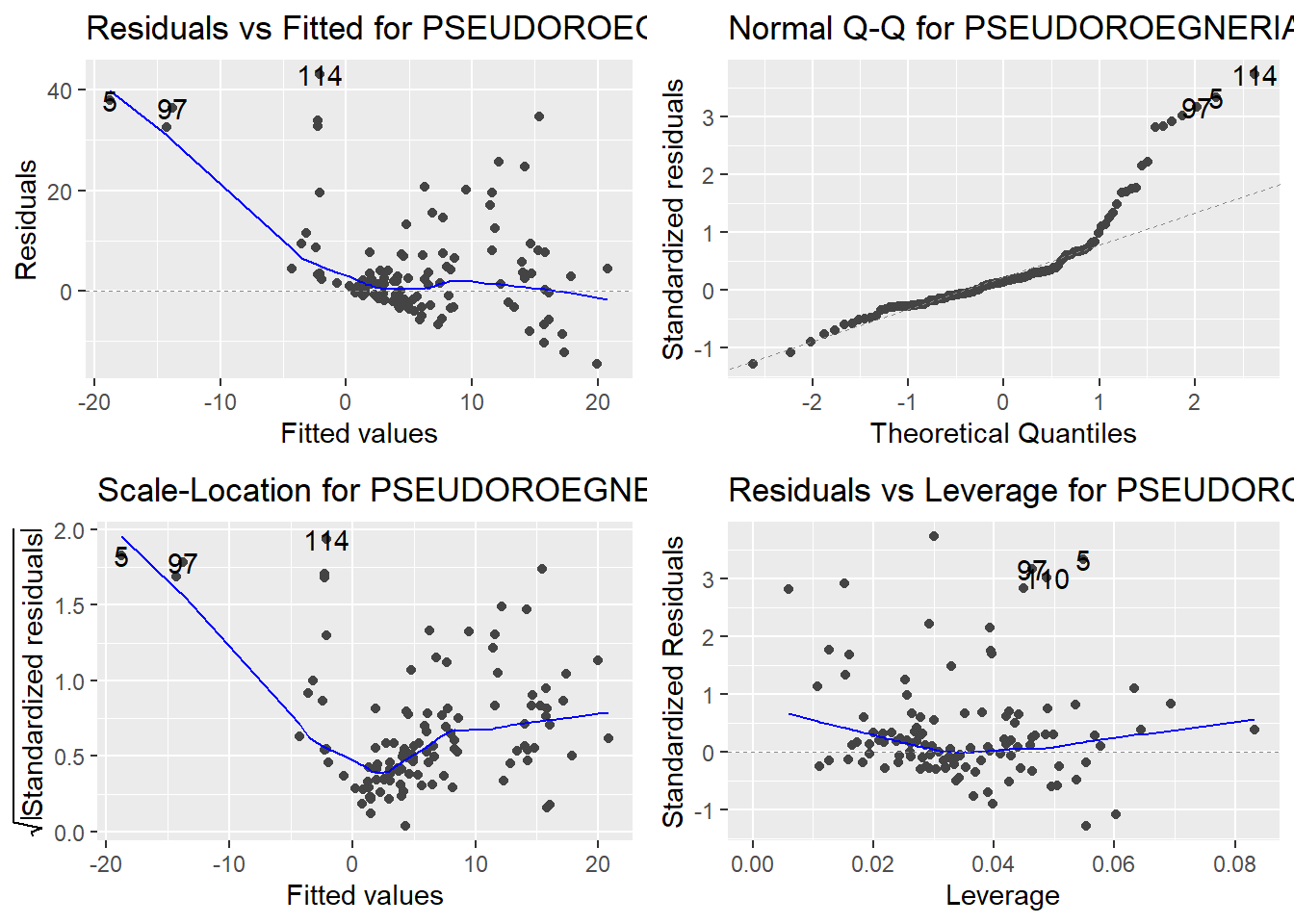
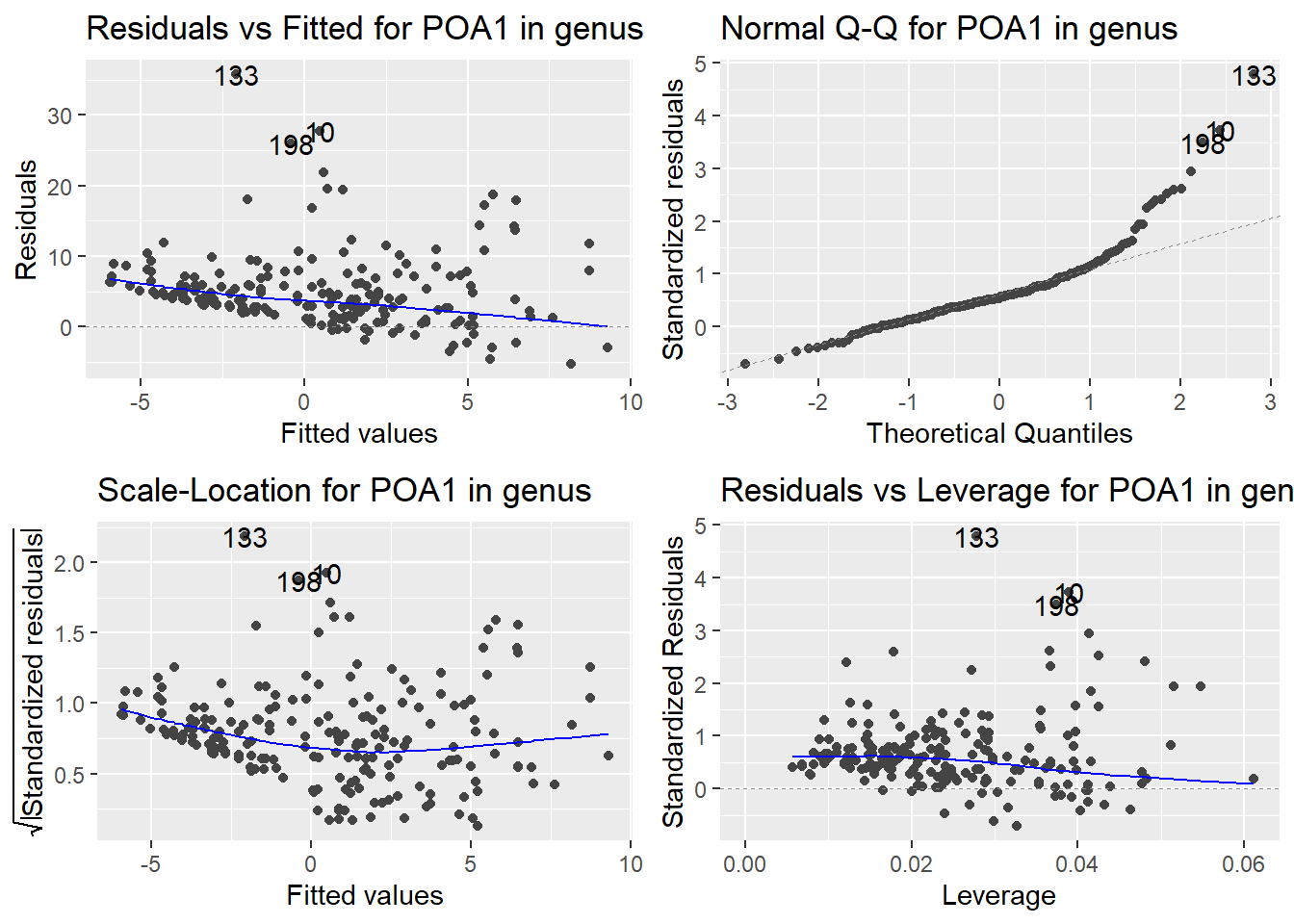
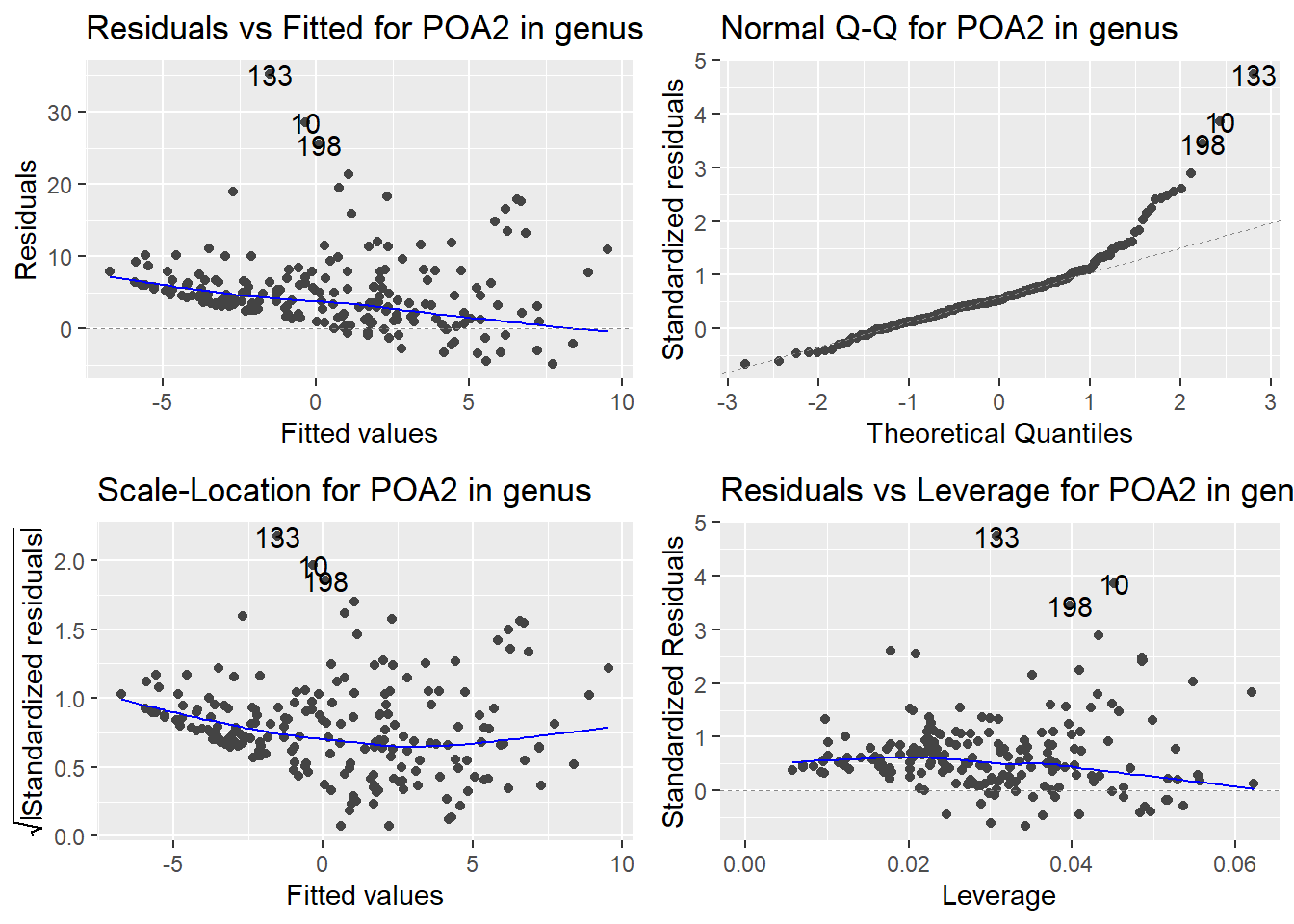
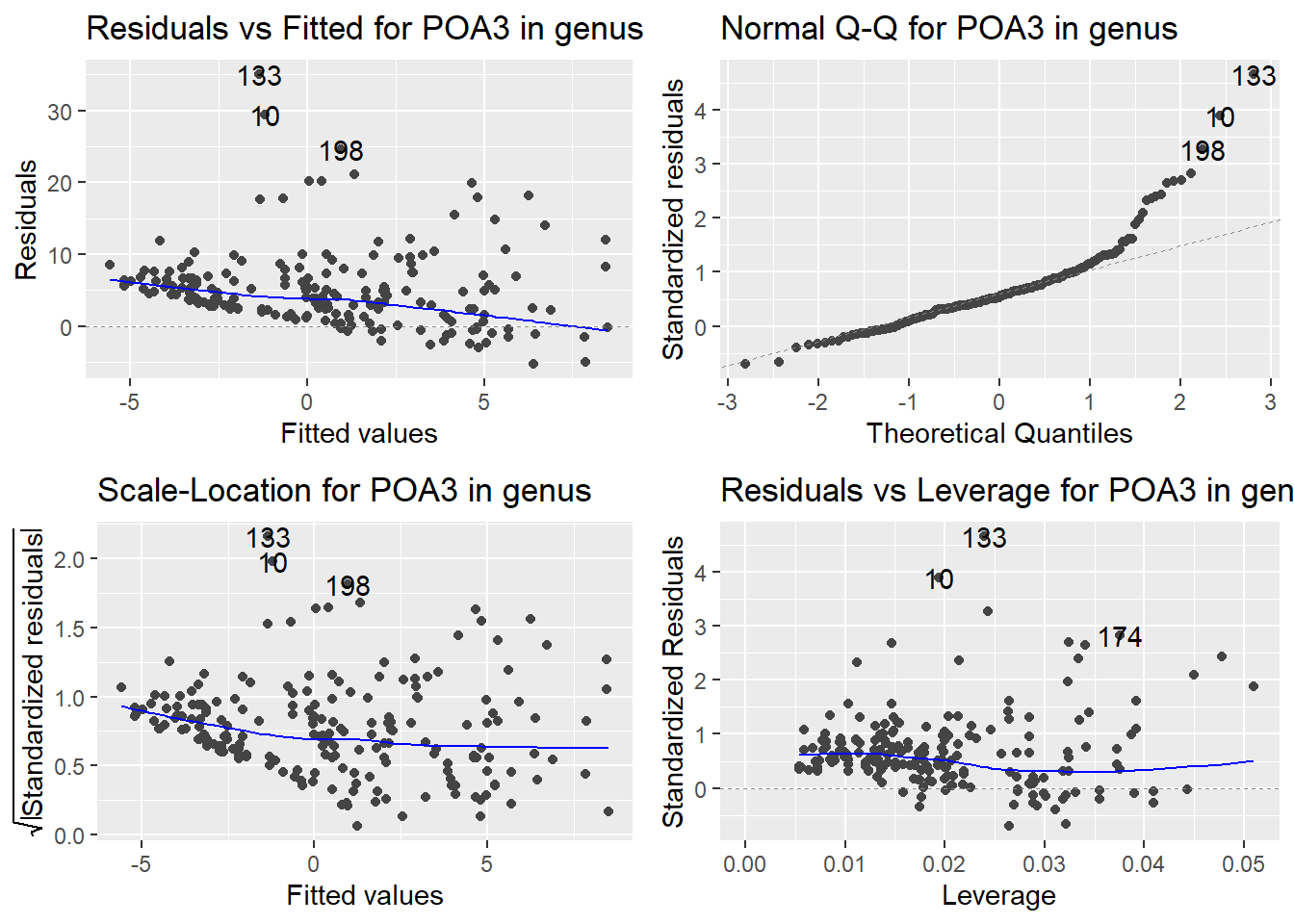
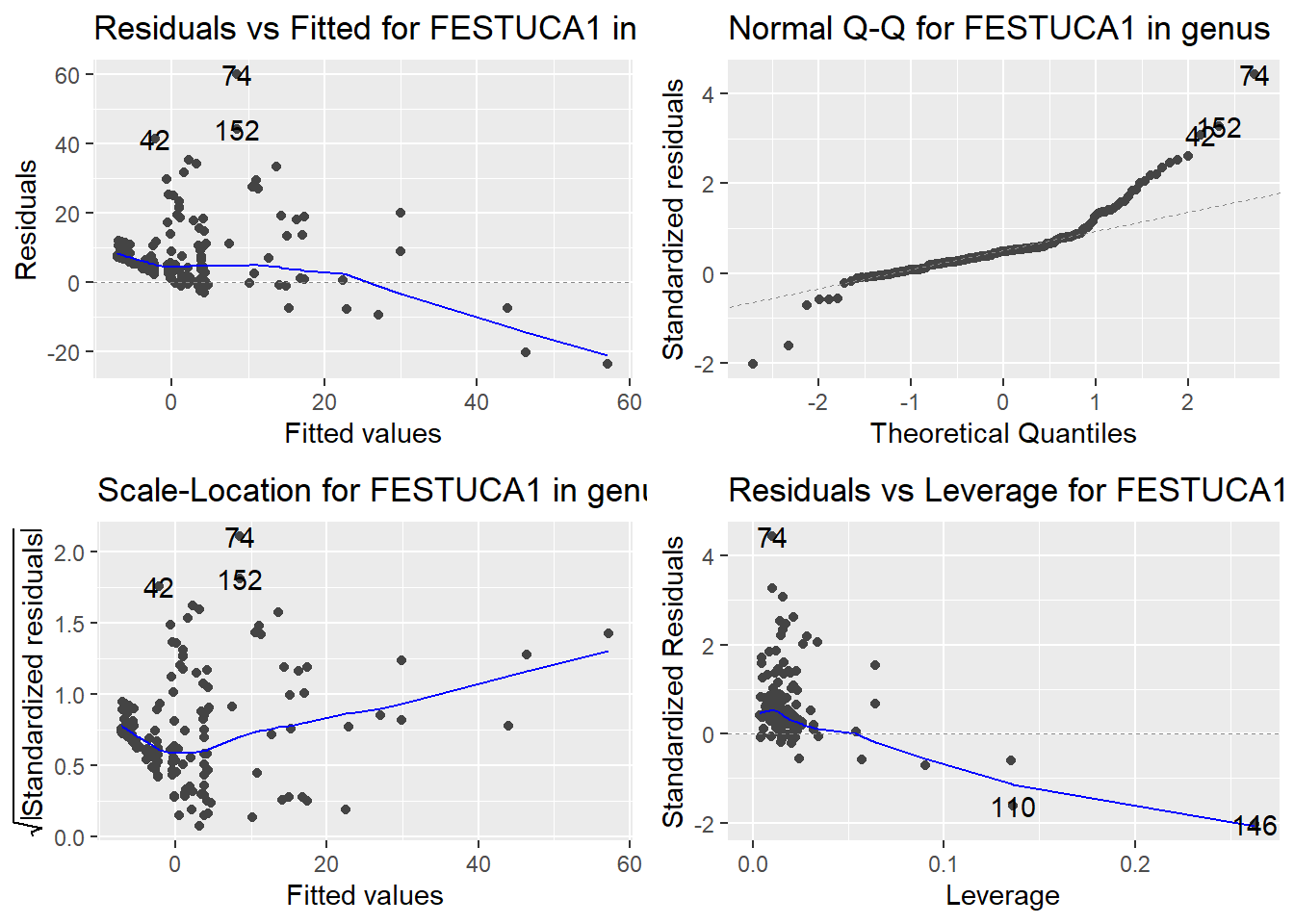
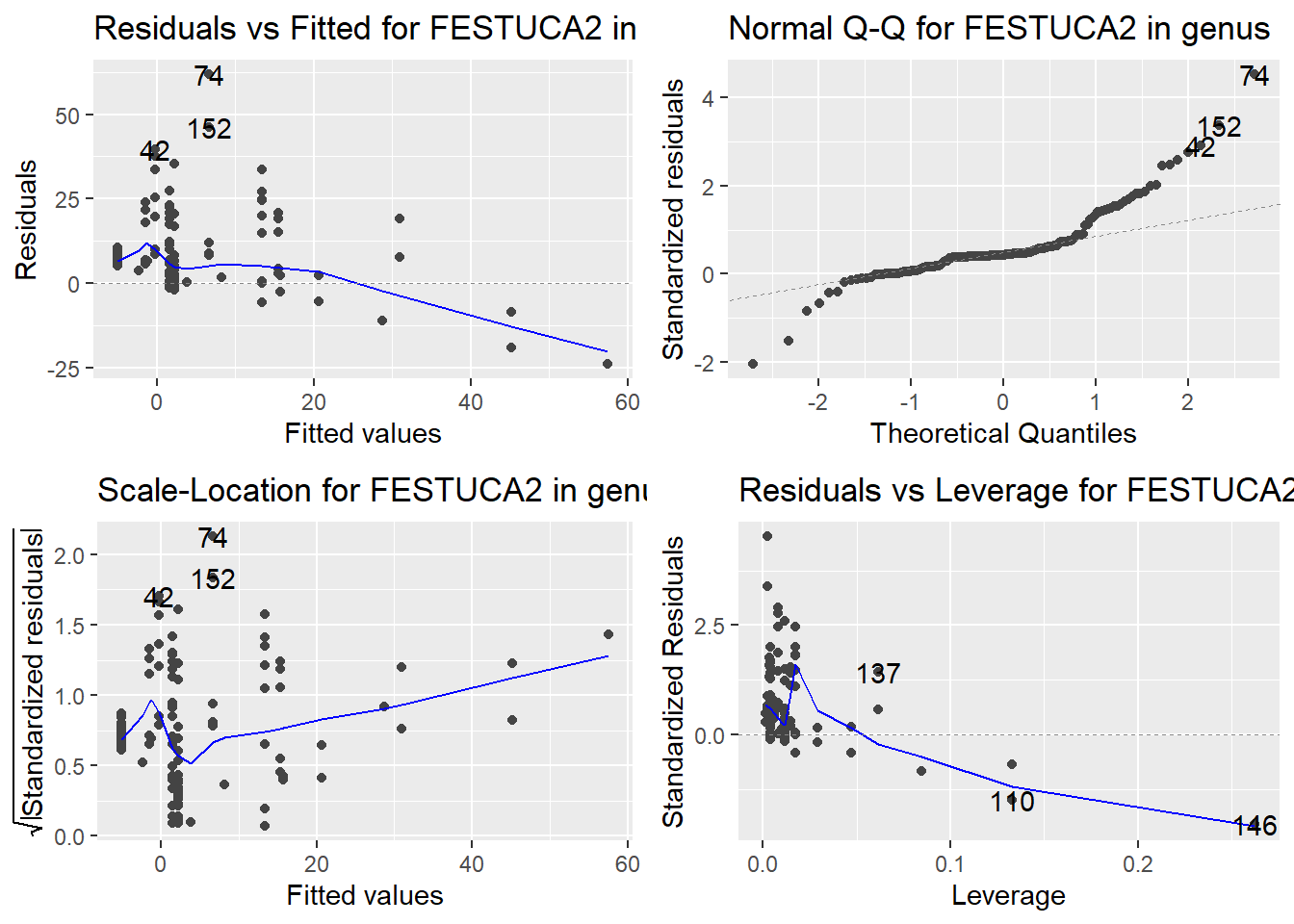
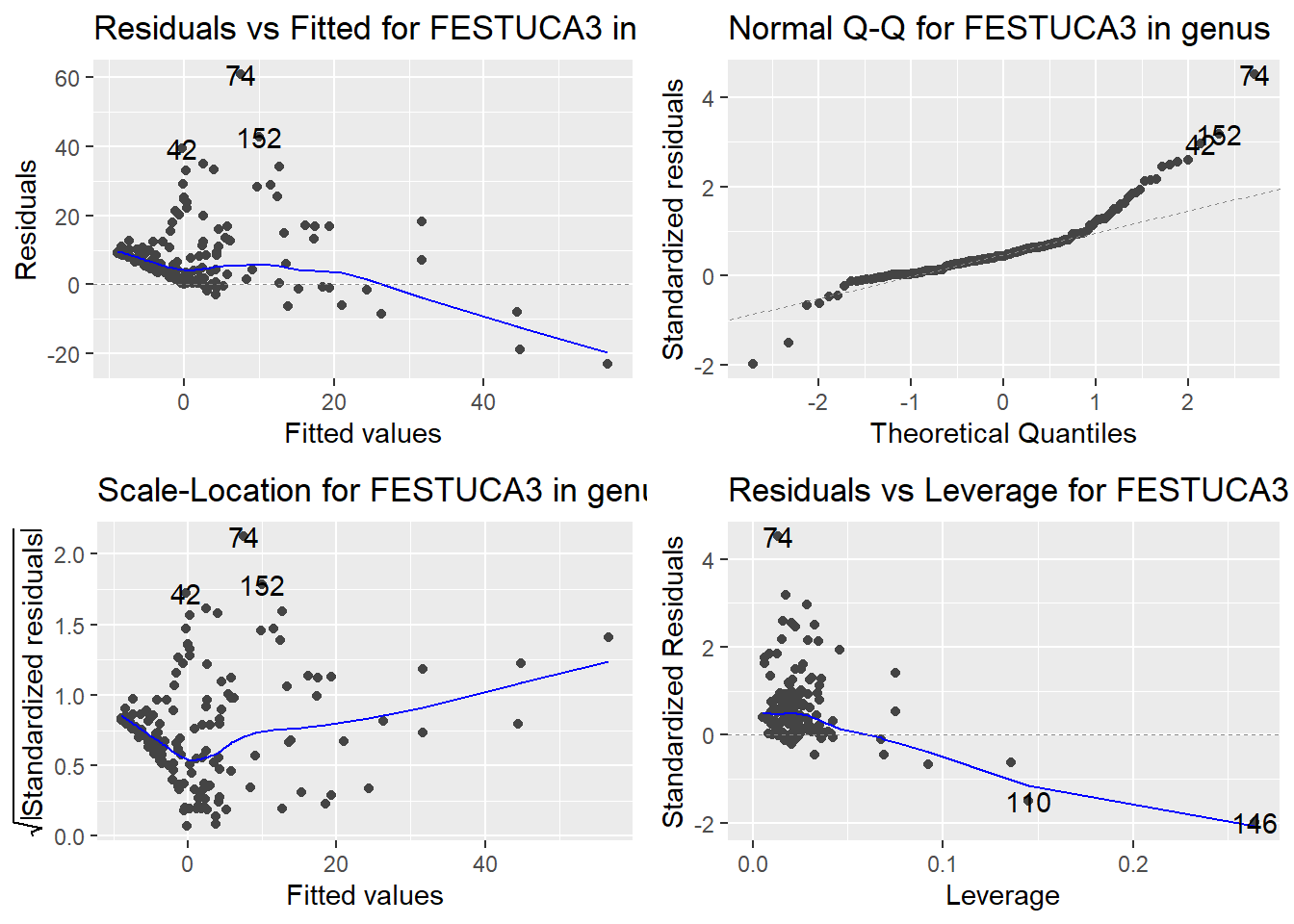
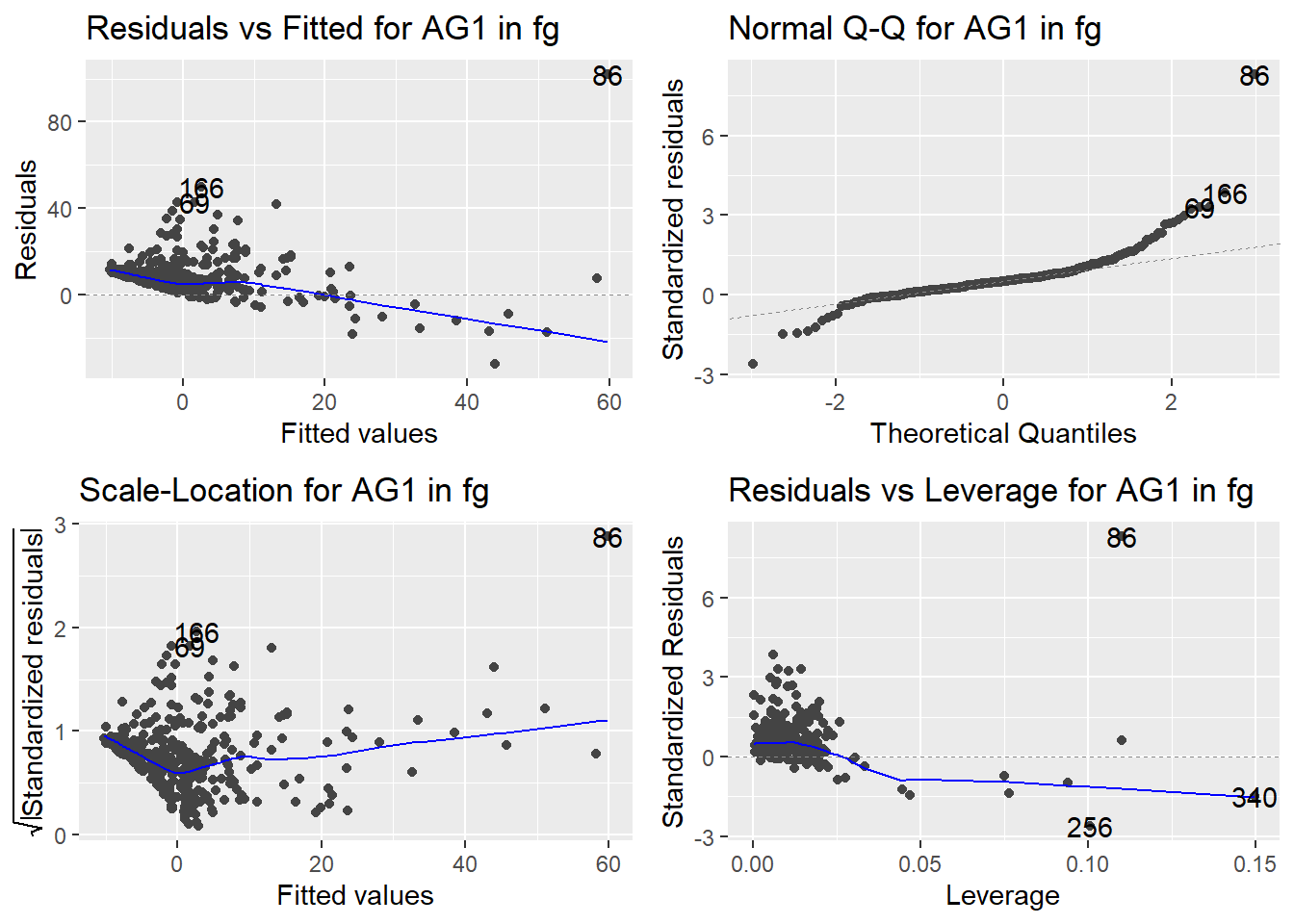
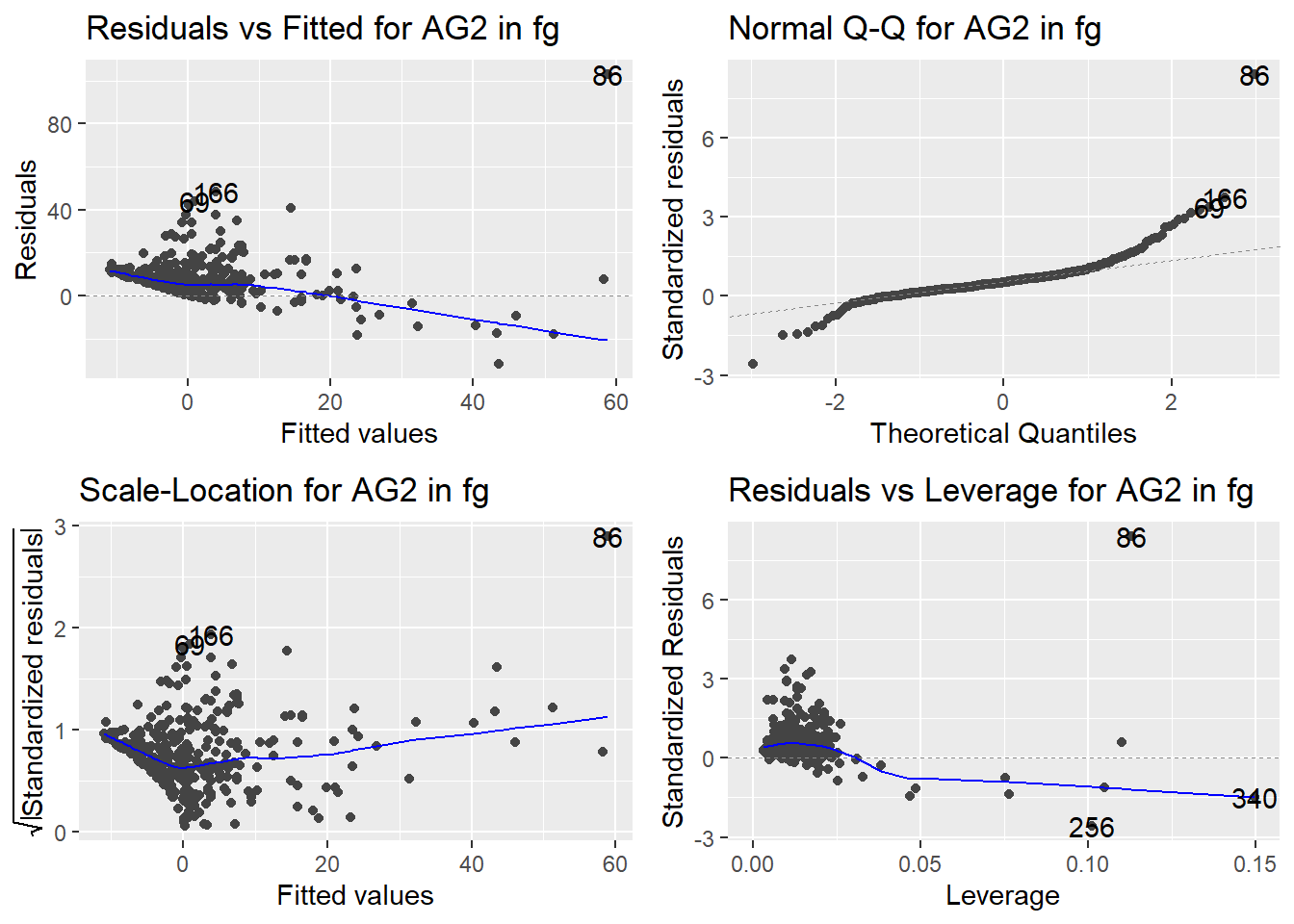
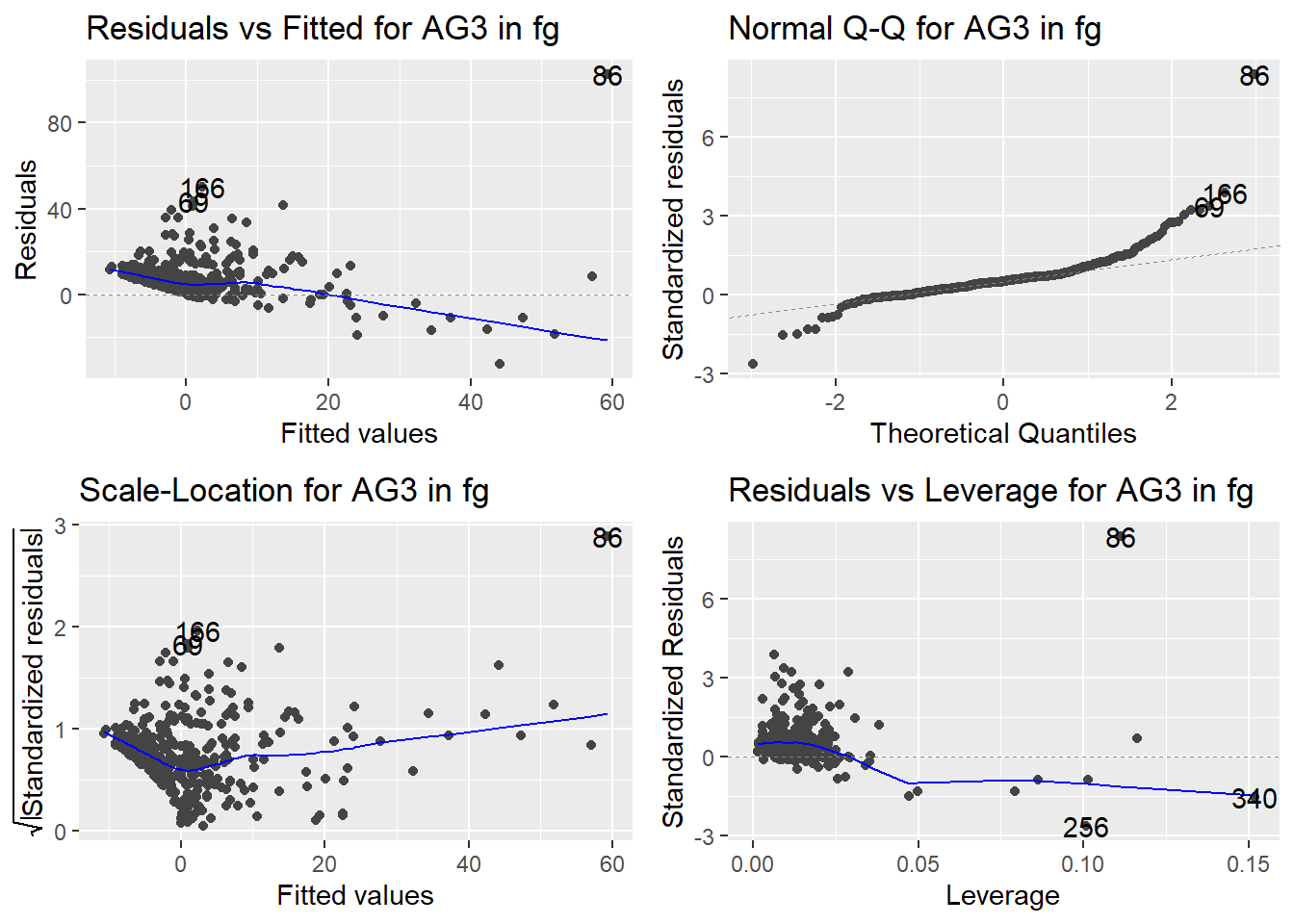
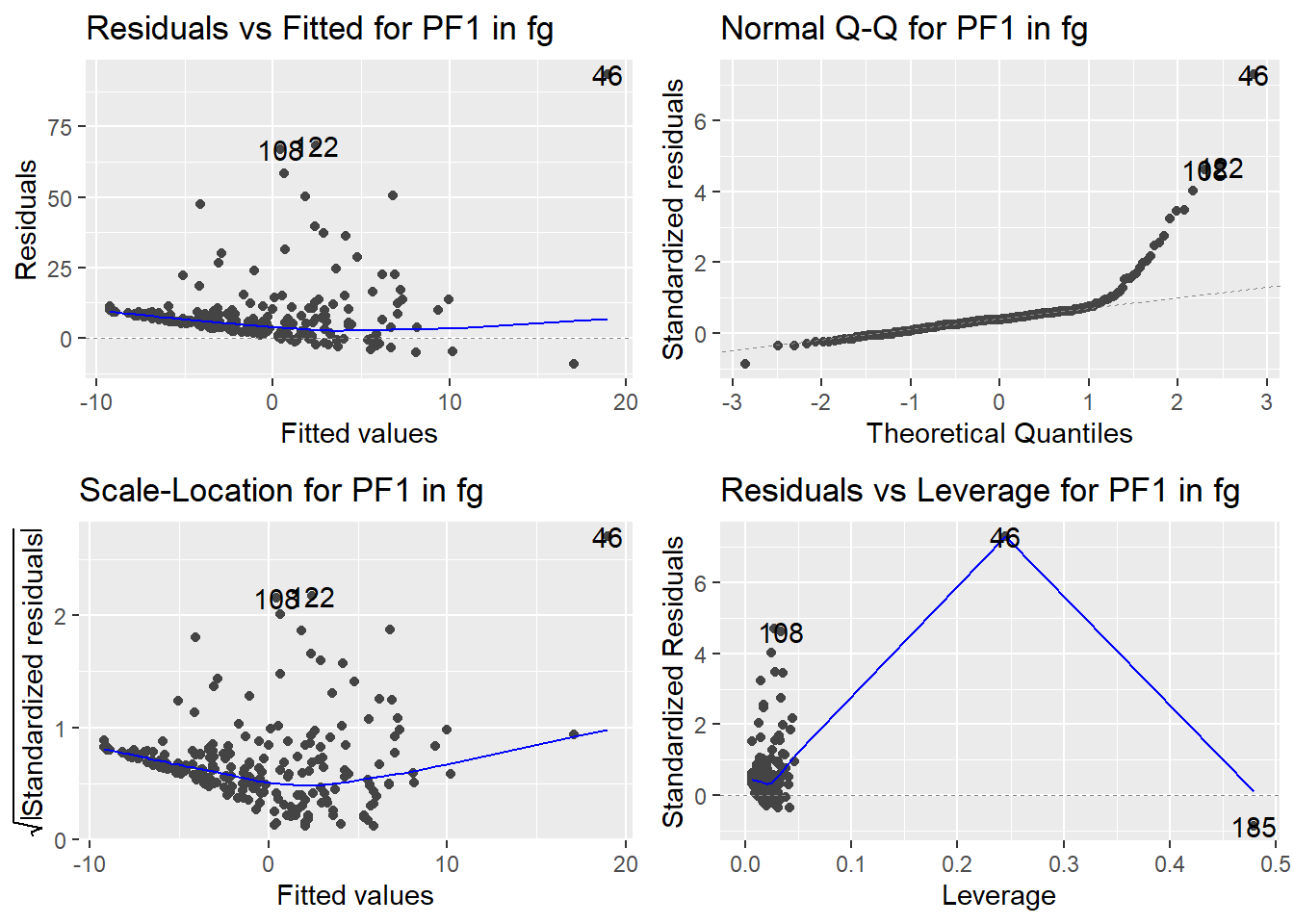
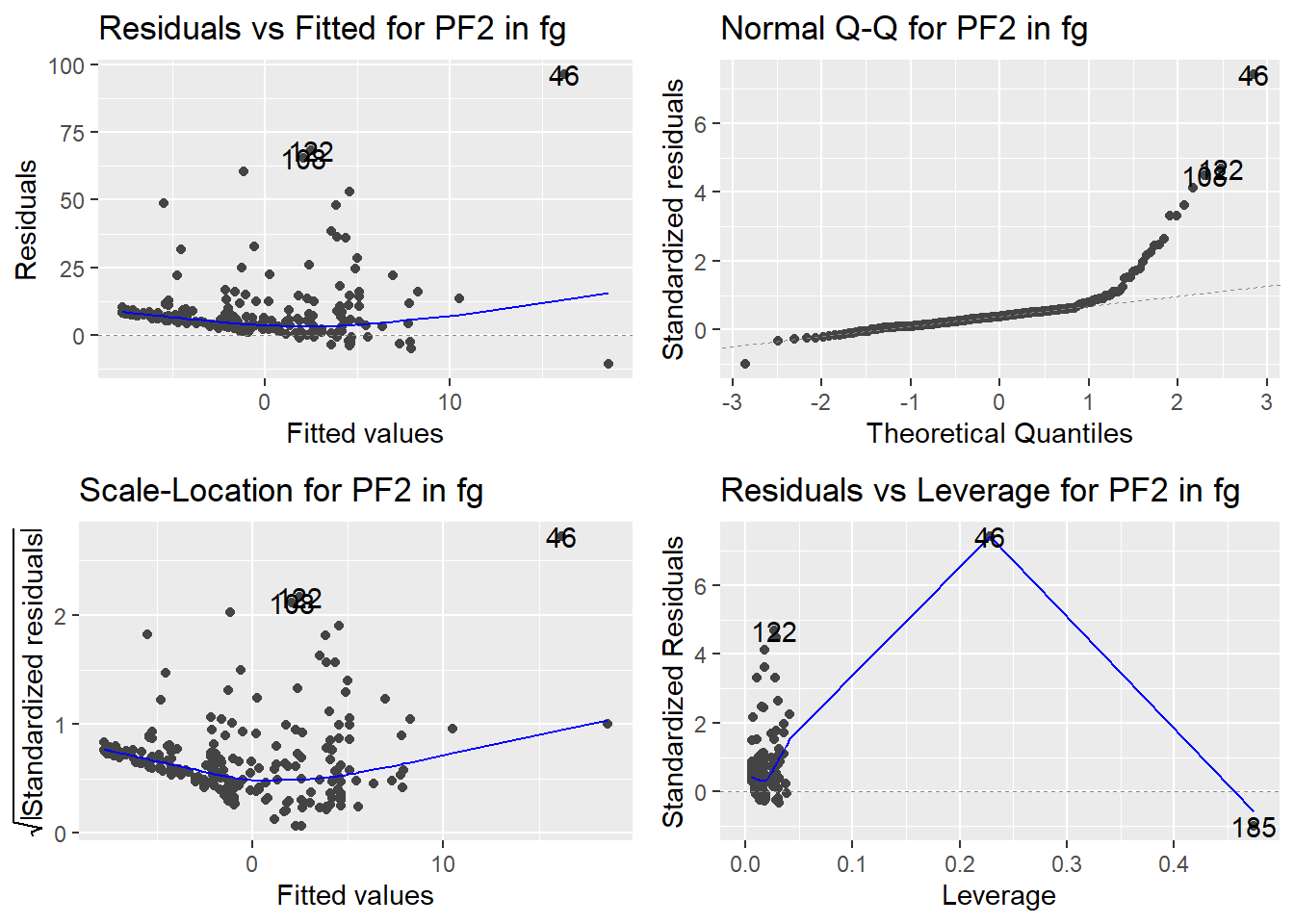
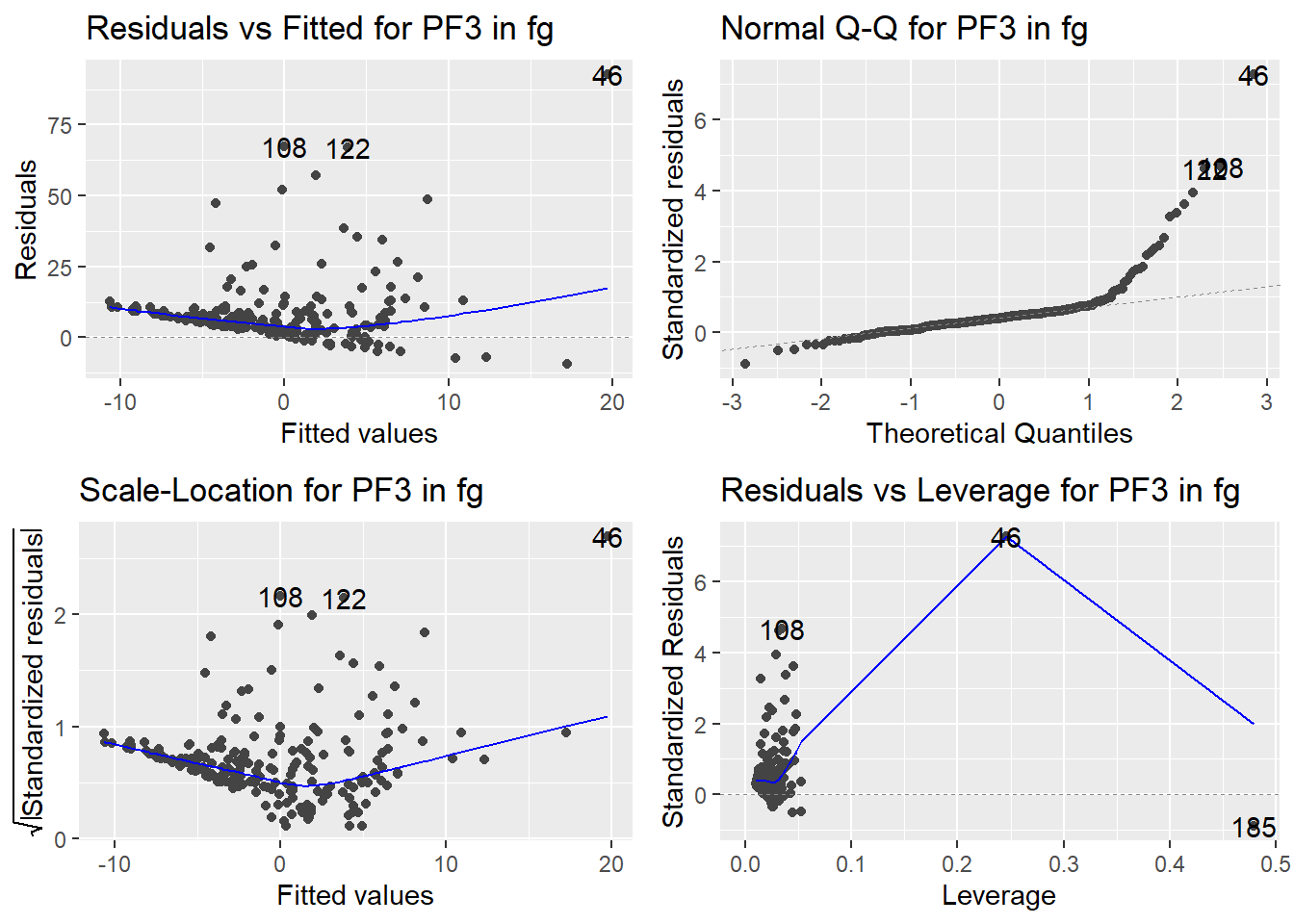
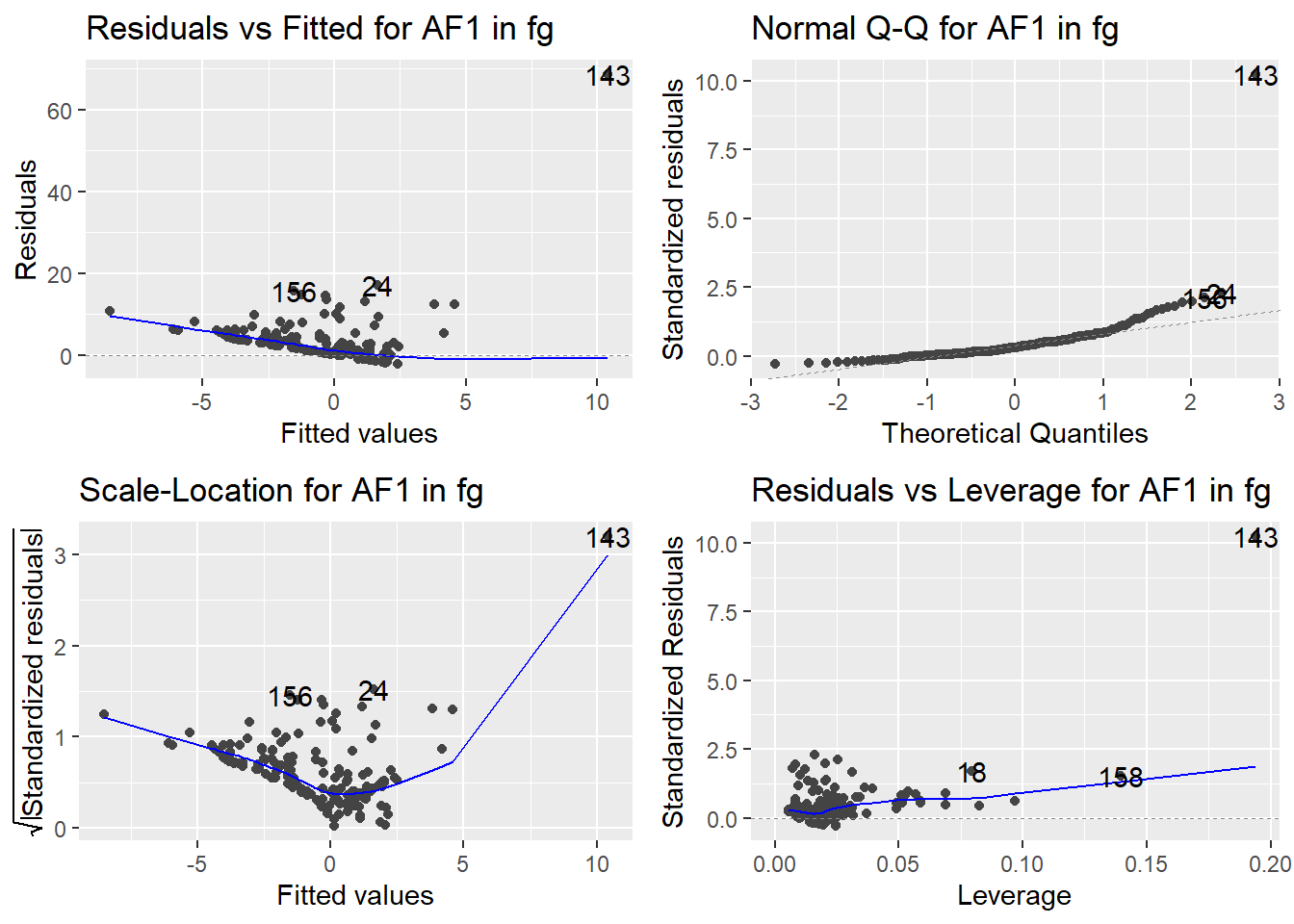
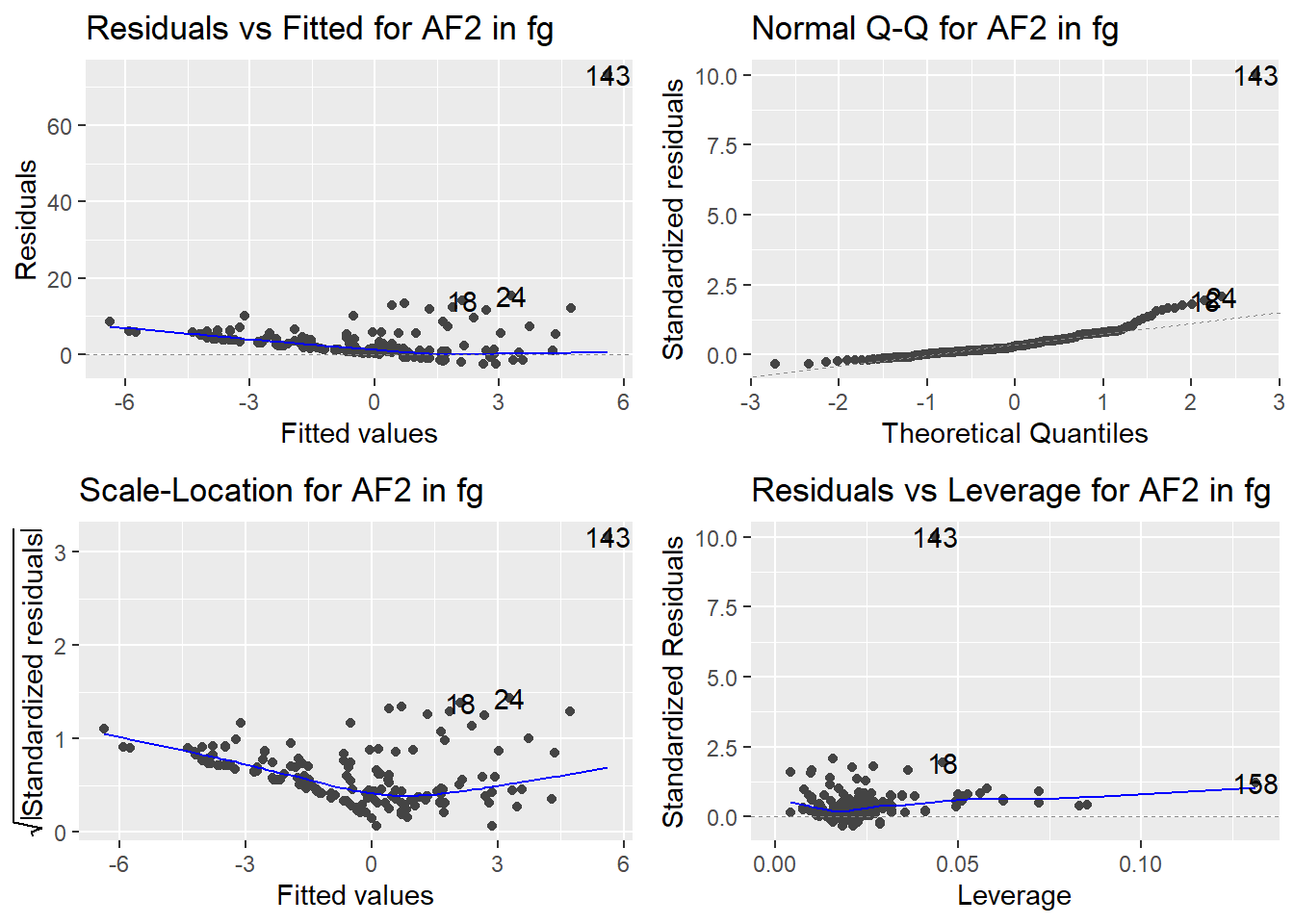
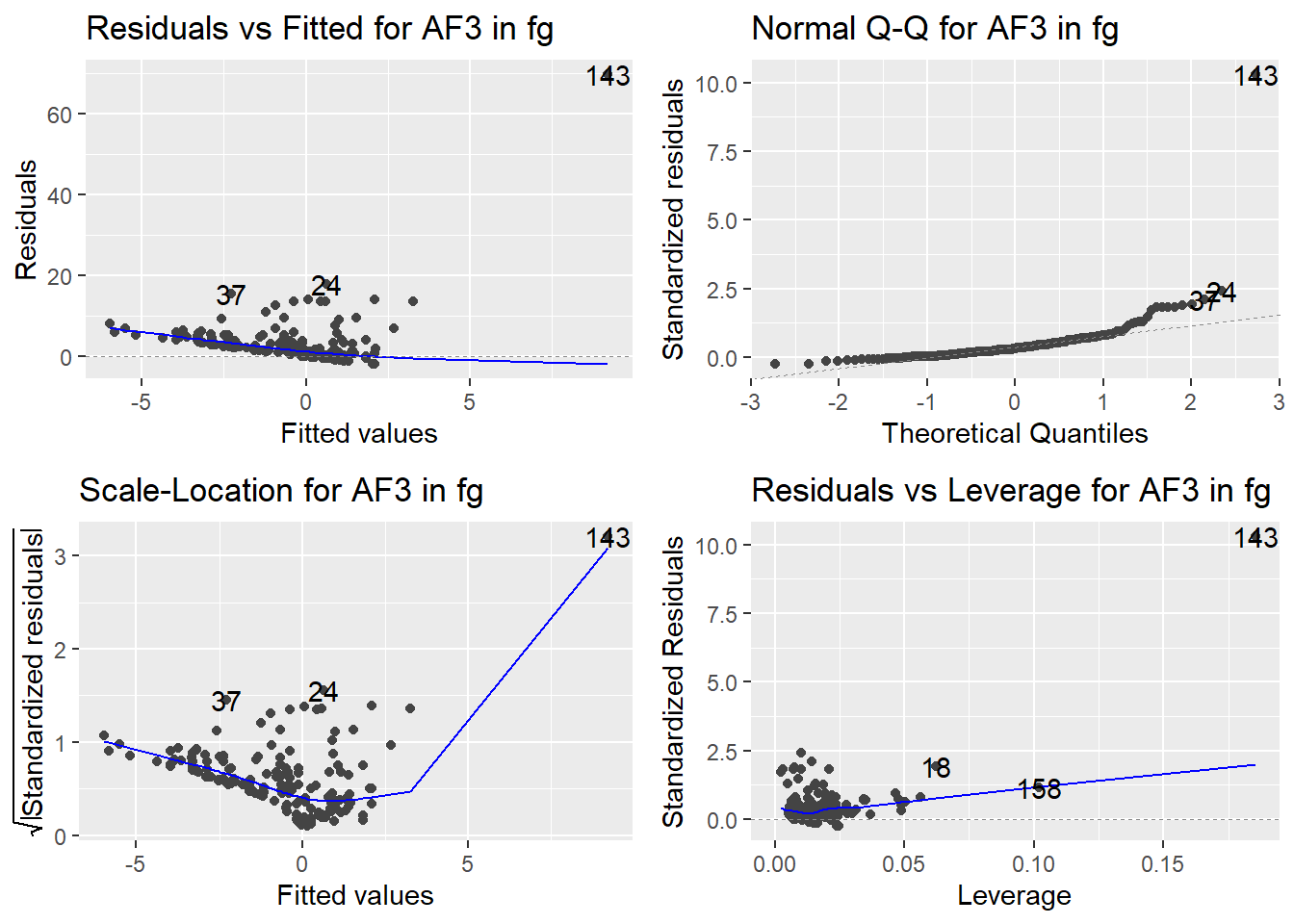
Here are the diagnostic plots for each of the linear models: Breusch–Pagan test (top left), Shapiro–Wilk test (top right), Durbin–Watson test (bottom left), and Cook’s distance (bottom right). Below the plots, I’ve also included each of the linear equations I’m using to predict biomass.
Code
library(ggfortify)library(gridExtra)plot_diagnostics <-function(model, model_name, group_name) { p1 <-autoplot(model, which =1)[[1]] +ggtitle(paste("Residuals vs Fitted for", model_name, "in", group_name)) p2 <-autoplot(model, which =2)[[1]] +ggtitle(paste("Normal Q-Q for", model_name, "in", group_name)) p3 <-autoplot(model, which =3)[[1]] +ggtitle(paste("Scale-Location for", model_name, "in", group_name)) p4 <-autoplot(model, which =5)[[1]] +ggtitle(paste("Residuals vs Leverage for", model_name, "in", group_name)) gridExtra::grid.arrange(p1, p2, p3, p4, ncol =2)}imap(all_models, function(model_list, group_name) {# Filter only models from this group that passed the R² criteria keep_models <- diagnostics_low_r2 %>%filter(group == group_name) %>%pull(model_name)# Subset model list to those models model_list_filtered <- model_list[names(model_list) %in% keep_models]# Plot only the retained modelswalk2(model_list_filtered, names(model_list_filtered), ~ {plot_diagnostics(.x, .y, group_name) })})
I’m having a hard time figuring out which plots are bad enough that they justify trying a different linear model. Did any of them stick out to you?
Are there any assumption tests that I should be taking with a grain of salt? Ryan mentioned that one of them might not matter as much since our main goal with the linear models is prediction.
Currently, I only have the top regression equation saved for each species, genus, etc. Before I go back and rerun the model dredging process to generate more equations, I wanted to check if you had any other suggestions on how I could improve the predictions.